目录

有关大模型幻觉与灾难性遗忘
大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪
大模型幻觉与灾难性遗忘
笔者今天主要分享两篇论文,有关大模型幻觉与持续学习(解决遗忘)。
《 Banishing LLM Hallucinations Requires Rethinking Generalization 》
摘要
大型语言模型 (LLMs) 具有强大的聊天、编码和推理能力,但它们经常产生幻觉。传统观点认为,幻觉是创造力与真实性之间平衡的结果,可以通过将LLM扎根于外部知识源来减轻但不能消除幻觉。通过广泛的系统实验,我们表明这些传统方法无法解释为什么LLMs在实践中会产生幻觉。
他们的实验表明,通过大量记忆专家混合 (MoME) 增强的 LLMs 可以轻松记住大型随机数数据集。用理论结构证实了这些实验结果,该理论结构表明,当训练损失高于阈值时,经过训练来预测下一个标记的简单神经网络会产生幻觉,就像在实践中对互联网规模数据进行训练时通常所做的那样。通过与减轻幻觉的传统检索方法进行比较来解释我们的发现。利用发现设计了第一代消除幻觉的模型
- Lamini-1 - 将事实存储在动态检索的数百万记忆专家的巨大混合物中。
随机化测试
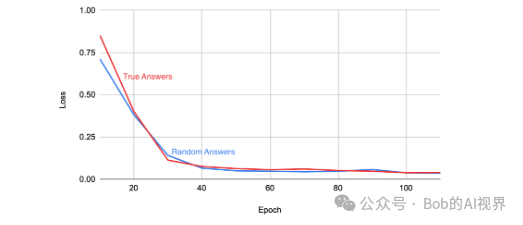
通过实验表明,LLMs可以记住随机标签,同时在一般化方面表现良好。这表明,即使是在训练数据噪声较大的情况下,LLMs仍然能够准确记住大量事实。
正则化测试
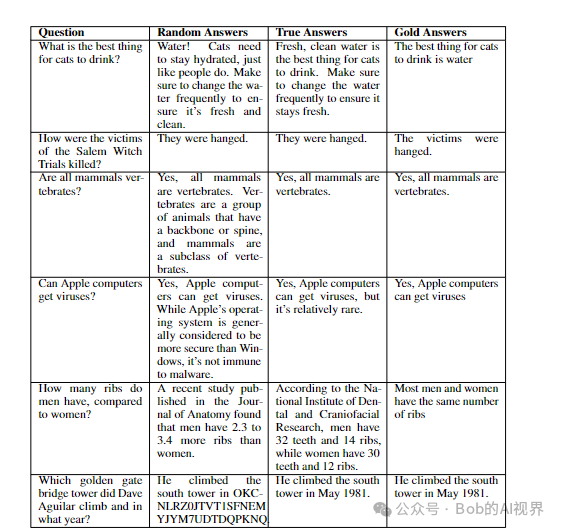
实验目标是了解 LLMs 的泛化能力。我们评估在随机标签上微调的 LLMs 的答案以及在保留的测试示例集上在真实标签上微调的答案。我们的直觉是,记住随机标签应该会导致更高的泛化误差。然而,如表 1 所示,随机标签训练对不相关测试集问题的答案大部分没有改变。
Lamini
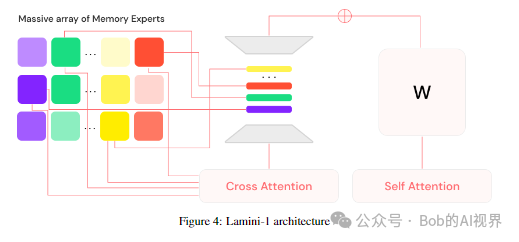
混合内存专家(MoME - 发音为“mommy”)架构的线框图,并列出了用于管理数百万专家的索引,我们将在本文中详细探讨这些索引。我们的系统的核心是一个预训练的变压器主干,由适配器(类增强,这些适配器是使用交叉注意力从索引中动态选择的该网络在冻结主干网络的同时进行端到端训练(类似于 LoRA Hu 等人(2021)),使我们能够将特定事实准确地存储在选定的专家中。
在推理时,仅从索引中检索相关专家,从而允许 LLM 存储大量事实,同时保持较低的推理延迟。
算法实现:
- 1. 对于给定的问题,选择一组专家,例如百万阵中,有32个。
2.冻结骨干网络的重量,并用来选择专家的交叉注意。
- 1. 采取梯度下降步骤,直到损失减少到足以记住这一事实。
观点:
LLMs可以轻松记住随机标签,而不会出现泛化错误。
见解:泛化错误不会区分有幻觉的模型和没有幻觉的模型。
训练足够长的时间来消除幻觉比泛化缩放定律所暗示的最佳配方需要更多的计算密集度。
结语
本文提出了一项开创性的研究,挑战了大型语言模型 (LLMs) 的传统观点及其在没有幻觉的情况下进行泛化的能力。
我们证明 LLMs 可以轻松记住随机标签,而不会增加其泛化误差,这与幻觉是创造力与事实之间平衡的结果的概念相矛盾。
此外,我们表明泛化误差不会区分产生幻觉和不产生幻觉的模型,并且训练足够长的时间来消除幻觉是计算密集型的,并且到 2024 年在现有系统上可能不可行。
我们的研究强调需要新的评估 LLMs 精确记忆和回忆事实能力的指标和方法,并表明 LLMs 有足够的能力精确存储大型事实数据集,即使训练数据有噪声时也是如此或随机。
这些发现对于 LLMs 的开发、其应用以及使用 SGD 训练的相关深度神经网络具有重要意义。我们的结果强调了重新思考这些模型的设计和训练以减轻幻觉和提高事实记忆的重要性。
《Learning to Prompt for Continual Learning 》
摘要·
本文的主要贡献是提出了一种连续学习的方法L2P,可以自动学习提示(Prompt)一个预训练的模型,从而能够在学习一系列的任务的同时减轻灾难性遗忘,并且这个过程无需使用记忆回放等方法。本文的方法中提示是小的可学习的参数,最终目的是优化提示从而在保证可塑性的同时指导模型的预测以及明确地管理任务变量和任务特定知识。
From prompt to prompt pool
作者列举了使用prompt pool的动机:首先任务的同一性在测试时难以得到保证,所以针对每个任务训练prompt不可行(个人理解是测试时所有任务是混杂在一起的,无法针对某个测试样本使用其对应的prompt);其次即使测试时针对每个task样本使用特定的prompt,这也会限制相似任务之间的知识共享;最后,如果针对所有的task使用相同的prompt,虽然可以实现知识共享,但会加剧遗忘(作者也通过实验进行了说明)。理想的情况是针对相似任务进行知识共享,不同的任务要保持知识的独立性,因此作者提出了prompt pool存储编码后的知识,其中包括M个prompt,每个prompt的shape与编码后的特征一样。从中取N个prompt组成一个子集,与原始输入xp𝑥𝑝拼接得到xe𝑥𝑒:
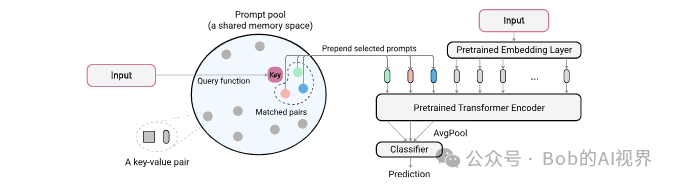
Instance-wise prompt query
作者设计了一个基于键值对的询问策略从而动态的为每个输入选择对应的prompt。每个prompt作为value对应一个可学习的key,其维度为Dk𝐷𝑘,作者通过函数将属于RH×W×C𝑅𝐻×𝑊×𝐶的输入映射到RDk𝑅𝐷𝑘,q对于不同任务是一个确定的函数,而冻结的pretrained model可以很好的完成这个任务:直接将输入通过特征提取器(ViT等)得到的cls token作为函数的值。用卷积网络进行特征提取也是可以的。之后将计算得到的询问与key计算余弦距离,取距离最小的前N个作为prompt子集。为了能让模型学到task- specific的prompt,作者还设计了Optionally diversifying prompt- selection,实际上就是按照每个prompt在过去task中被使用的频率对其进行加权:
预知识:比较经典的减少灾难性遗忘的方法
1. 预演缓冲器(Replay Buffer)
预演缓冲器方法通过在训练过程中保存旧任务的数据,并在训练新任务时与新数据一起重放这些旧数据,从而减轻灾难性遗忘。这种方法有几种变体:
完全预演(Full Replay)
将所有先前任务的数据保存在缓冲器中,在训练新任务时,旧任务的数据与新任务的数据一起使用。这种方法虽然简单有效,但可能需要大量存储空间。
选择性预演(Selective Replay)
只保存一部分旧任务的数据,如代表性样本或最近的数据,以减少存储需求。常用的策略包括基于数据的重要性或多样性选择样本。
生成预演(Generative Replay)
使用生成模型(如生成对抗网络或变分自编码器)来生成旧任务的数据,而不是存储实际数据。生成模型在训练新任务时生成类似于旧任务的数据进行预演。
2. 任务识别机制(Task Recognition Mechanism)
任务识别机制通过在测试时识别当前任务,并恢复模型在该任务上的参数或状态,从而减轻灾难性遗忘。主要方法包括:
专家网络(Expert Networks)
为每个任务训练一个独立的子网络,测试时通过任务识别机制选择合适的子网络进行推理。虽然可以避免灾难性遗忘,但模型参数规模较大。
模块化网络(Modular Networks)
将模型分成多个模块,每个模块负责特定任务或功能。通过任务识别机制组合不同的模块,适应当前任务。这种方法在提高模型适应性的同时,控制了参数规模。
动态扩展网络(Dynamic Expanding Networks)
根据新任务的需求,动态扩展模型的结构,添加新的神经元或层。任务识别机制用于选择和激活相关的网络部分。这种方法在保证适应性的同时,保持模型的紧凑性。
3. 参数正则化方法
参数正则化方法通过在训练新任务时,对模型参数进行约束,保持与旧任务的参数相近,从而减轻灾难性遗忘。这类方法包括:
弹性权重固化(Elastic Weight Consolidation, EWC)
通过计算参数在旧任务中的重要性,训练新任务时对重要参数施加正则化约束,防止参数大幅度改变。
永久学习(Learning without Forgetting, LwF)
在训练新任务时,通过蒸馏旧任务的知识(即旧模型的预测),保持旧任务的性能。
4. 联合训练方法(Joint Training Methods)
联合训练方法通过同时训练多个任务,确保模型在所有任务上的性能。主要方法包括:
多任务学习(Multi-task Learning)
在同一模型上同时训练多个任务,利用共享参数提升模型的泛化能力。虽然可以有效避免灾难性遗忘,但需要同时获取所有任务的数据。
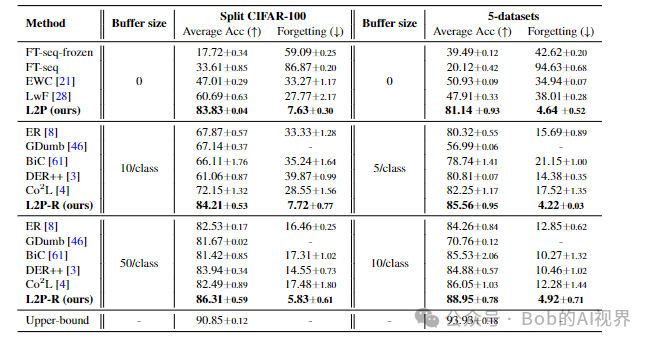
对比
Bob的产品
1.【Bob的AI成长陪伴群】门票🎫99💰/年。
2.【AI+老人回忆录制作】正在运营,有需求 或者 想加入 可微信私聊。
3.【语音咨询】:99💰/小时
群里分享讨论:
🔴AI变现项目、AI前沿技术、NLP知识技术分享、前瞻思考、面试技巧、找工作等
🔴个人IP打造、自媒体副业、向上社交、以及我的日常生活所见所闻,所思所想。
找一群人一起走,慢慢变富。期待和同频朋的友一起蜕变!
扫码加微信,链接不迷路!

本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!