目录
实现架构
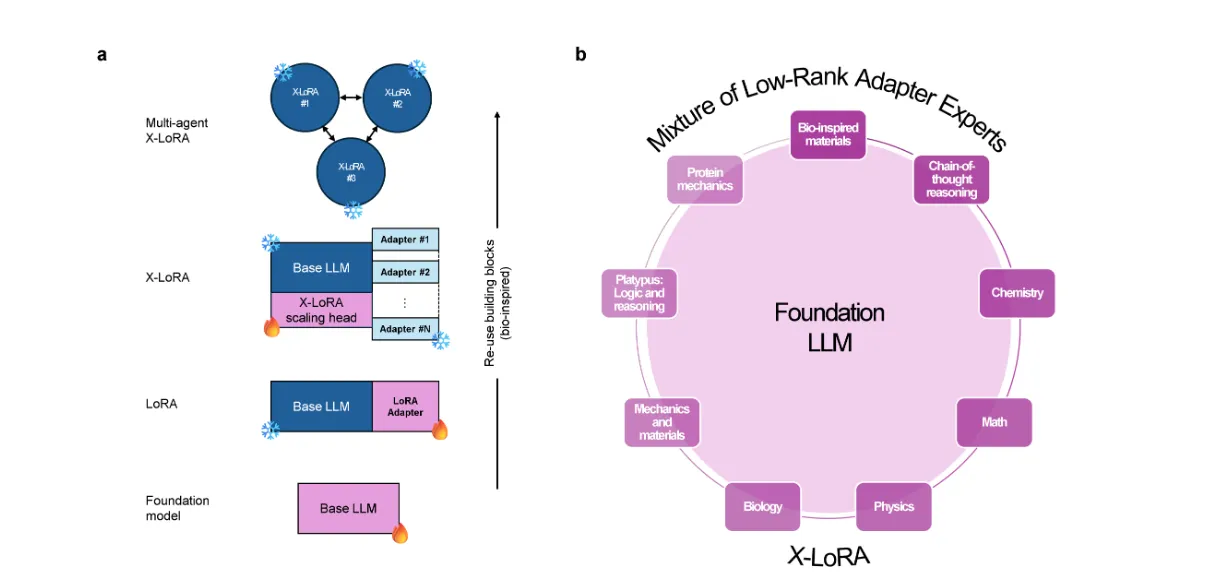
X-LoRA通过动态混合预训练的低秩适配器专家(LoRA adapters)来组合不同的适配器。这些适配器在不同的领域接受了专门的训练,以获得特定的专业知识。X-LoRA模型使用一个可训练的缩放头(scaling head),它利用模型的隐藏状态来预测每个适配器的缩放权重。然后,在第二次前向传递中,模型使用这些缩放权重来混合不同的适配器专家,从而根据问题的上下文重新配置其专业知识。
这种方法允许模型在处理任务时,根据需要激活和混合不同的专家,从而实现高度的专业化和灵活性。例如,在回答有关蛋白质力学的问题时,模型可能会更多地依赖蛋白质力学适配器,而在处理涉及多个领域的问题时,它可以动态调整适配器的混合,以提供更全面和准确的答案。
此外,X-LoRA模型采用双重前向传递的算法,首先“思考”问题并重新配置自身,然后再做出响应,这增强了模型的“自我意识”和适应能力。尽管X-LoRA模型的参数数量相对较少(70亿参数),但它能够跨多个科学领域进行推理,显著提高了生成创新解决方案的能力。这种方法还可以指导开发替代模型架构,例如,将重新配置策略推广到模型的一部分或整个模型。
双重前向传递
X-LoRA模型通过实施双重前向传递算法来实现“思考”问题并重新配置自身。在第一次前向传递中,模型处理输入并计算隐藏状态。这些隐藏状态被提供给X-LoRA的缩放头(scaling head),这是一个可训练的组件,它使用这些状态来预测每个适配器的缩放权重。然后,在第二次前向传递中,模型使用这些缩放权重来混合不同的适配器专家,从而根据问题的上下文重新配置其专业知识。
这种双重传递的方法允许模型在回答问题之前“思考”和调整其结构,这被视为一种简单的“自我意识”实现。通过这种方式,模型能够适应性地调整其内部结构,以最佳地解决手头的任务。尽管X-LoRA模型的参数数量相对较少(70亿参数),但它能够跨多个科学领域进行推理,显著增强了生成创新解决方案的能力。这种方法还可以指导开发替代模型架构,例如,将重新配置策略推广到模型的一部分或整个模型。
本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!