目录

新一代模型微调方案LLama-Pro ,快来围观!!!
大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪
LLAMA PRO论文笔记
直达链接:
摘要
这篇论文介绍了一种名为LLAMA PRO的新型后预训练方法,用于增强大型语言模型(LLMs)在特定领域的性能,同时保持其原有的通用能力。通过扩展Transformer块来增加模型的深度,从而在不牺牲原有性能的情况下,提升模型在编程、数学和一般语言任务中的表现。LLAMA PRO模型是在LLAMA2-7B的基础上通过块扩张方法构建的,并在编程、代码和数学方面表现出色。此外,本文还介绍了一种指令版的LLAMA PRO- INSTRUCT,它在各种基准上达到了先进的性能。实验结果表明,LLAMA PRO不仅在通用语言任务上保持了高水平的表现,而且在编程和数学任务上的性能也得到了显著提升。
先前微调方法的不足
之前的微调方法,如指令调优(Instruction Tuning)和参数高效调优(Parameter-Efficient Fine- Tuning),如LoRA,虽然能够增强大型语言模型(LLMs)在特定领域的性能,但也存在一些缺点:
-
指令调优(Instruction Tuning):这种方法通常需要大量的指令数据来进行调优,以产生高质量的输出。但是这种方法需要很高的计算资源。
-
参数高效调优(Parameter-Efficient Fine-Tuning):如LoRA等方法虽然能够以较低的计算成本适应预训练模型到新的领域,但这些方法通常在预训练阶段之后应用,可能会导致模型在适应新领域的同时,损失一部分原有的通用能力。
LLAMA PRO 架构
LLaMA PRO通过在现有的LLM中添加额外的Transformer块来增加模型的深度,这些块在初始化时被设置为零,并在domain- specific语料库上进行微调。这种方法使得模型能够在学习新知识的同时,避免了对原有知识的遗忘。
此外,LLaMA PRO还采用了指令跟随(Instruction Following)技术,通过大约80M tokens的supervised instruction tuning,进一步增强了模型的能力。这种技术使得模型能够更好地理解和执行人类的指令,从而在各种任务中表现出更好的性能。
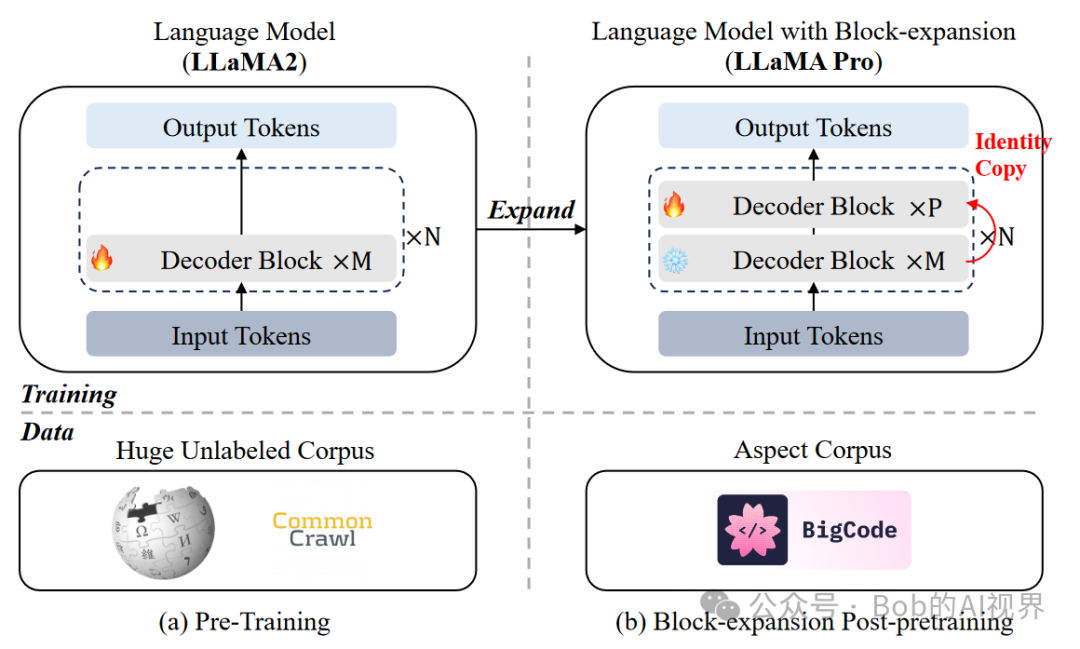
如图(a)所示,从一个大型的语言模型(LLM)开始,该模型在庞大的未标注语料库上进行了预训练,从而获得了强大的通用能力。为了方便起见,文章选择了现成的LLaMA2。(b) 采用了骨干扩展,并使用特定领域语料库对扩展的身份块进行了微调,同时冻结了从基础模型继承的块。经过后预训练的模型可以像往常一样用于指令调优。
具体实现
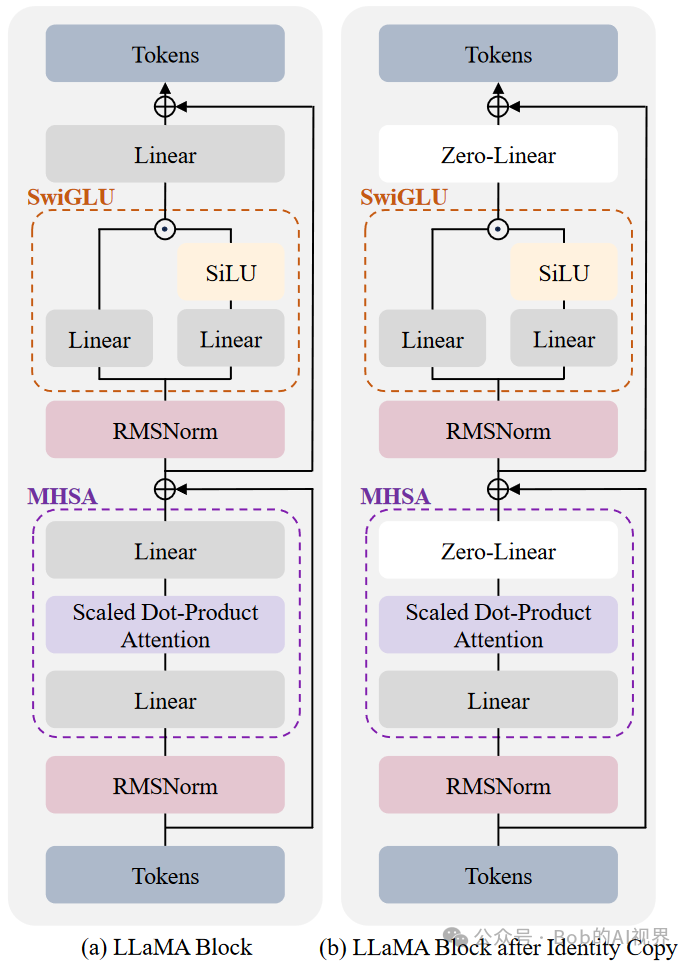
-
模型扩展 :在现有的LLaMA模型中,每组Transformer块之后添加一个Identity Block(身份块,如上图)。这些块在初始化时被设置为零,以确保模型在扩展后保持相同的输出。
-
分组和复制 :将原始模型的Transformer块分成多个组,对于每个组,创建原始块的上层副本(即身份块),并将其堆叠在原始组之上。这个过程是逐层进行的,以保持Transformer模型的结构特性。
-
身份块定义 :身份块被定义为恒等函数,即对于任何输入,身份块输出的值与输入相同。这样可以确保在添加新块后,模型的输出行为不会改变。
-
初始化 :新添加的块中的线性层被初始化为零,以实现身份映射。这样,在训练过程中,这些新块可以学习新的知识,而不会影响或覆盖原有的知识。
-
微调 :在添加新块之后,只对新增的块进行微调,而保持原始的块冻结。这样可以确保模型在增强特定领域能力的同时,不会牺牲其原有的通用能力。
-
训练和优化 :使用domain-specific的语料库对扩展后的模型进行微调。在这个过程中,只更新新添加的块,而原始的块保持不变。
效率和效果
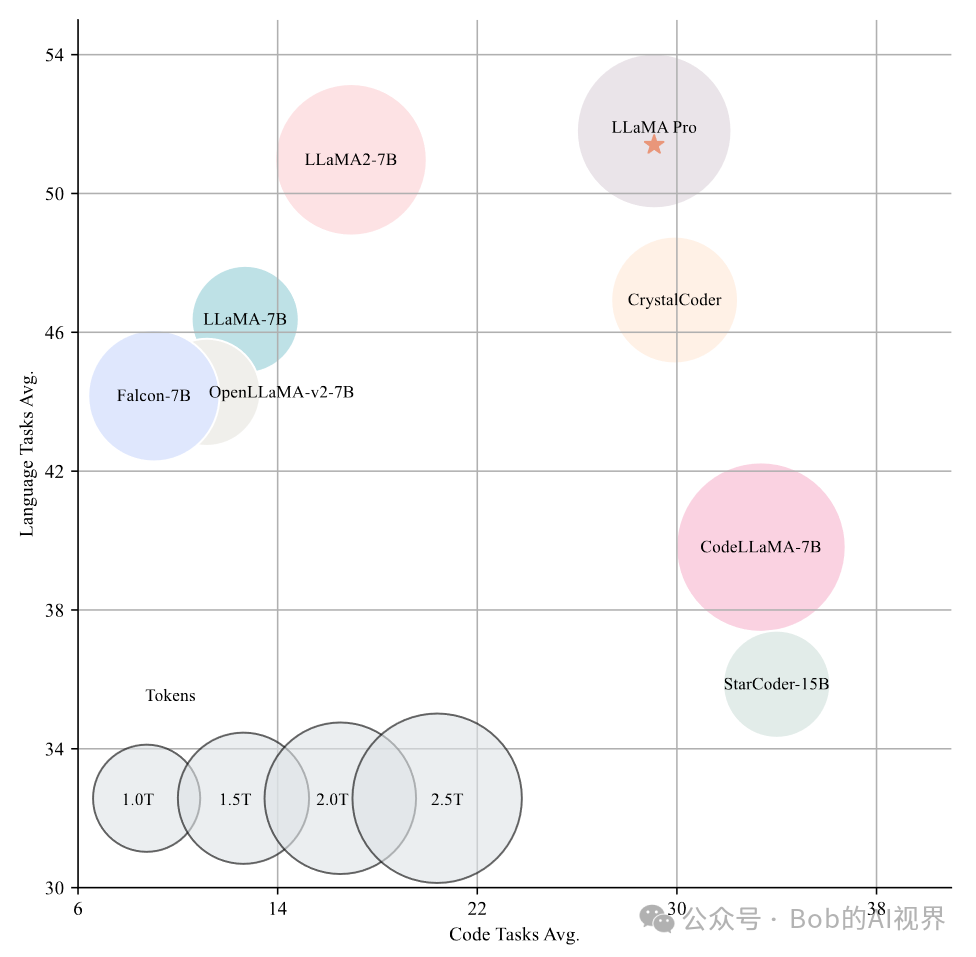
如图所示,横轴为Code Tasks Avg,纵轴为Language Tasks Avg,圆点的尺寸与训练的令牌数量成正比。
不同训练策略评估结果的比较,报告了在通用任务和法律特定任务上的表现。可以看出Add 8 Block这个超参数下平局分数最高。
Bob 的产品
1.【Bob 的 AI 成长陪伴群】门票 🎫99💰/年。
2.【AI+老人回忆录制作】正在运营,有需求 或者 想加入 可微信私聊。
3.【语音咨询】:99💰/小时
群里分享讨论:
🔴AI 变现项目、AI 前沿技术、NLP 知识技术分享、前瞻思考、面试技巧、找工作等
🔴 个人 IP 打造、自媒体副业、向上社交、以及我的日常生活所见所闻,所思所想。
找一群人一起走,慢慢变富。期待和同频 朋的 友一起蜕变!
扫码加微信,链接不迷路!

本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!