目录

新型AI大模型微调方式:ReFT 表征微调
大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪
ReFT (表征微调)
本文主要介绍 ReFT(表征微调),这是一种比 PeFT(参数高效微调)效果更好的新的大语言模型微调技术。
背景
PEFT
PEFT (Parameter-Efficient Fine-Tuning,参数高效微调) 是一种仅微调少量模型参数或添加额外的模型参数,固定大部分预训练参数,从而大大降低计算和存储成本的方法。
ReFT
ReFT (Representation Finetuning) 是一组专注于在推理过程中对语言模型的隐藏表示学习干预的方法,而不是直接修改其权重。
相比 PEFT,ReFT 不改变原模型权重,所消耗的算力资源更少,效果也不错。
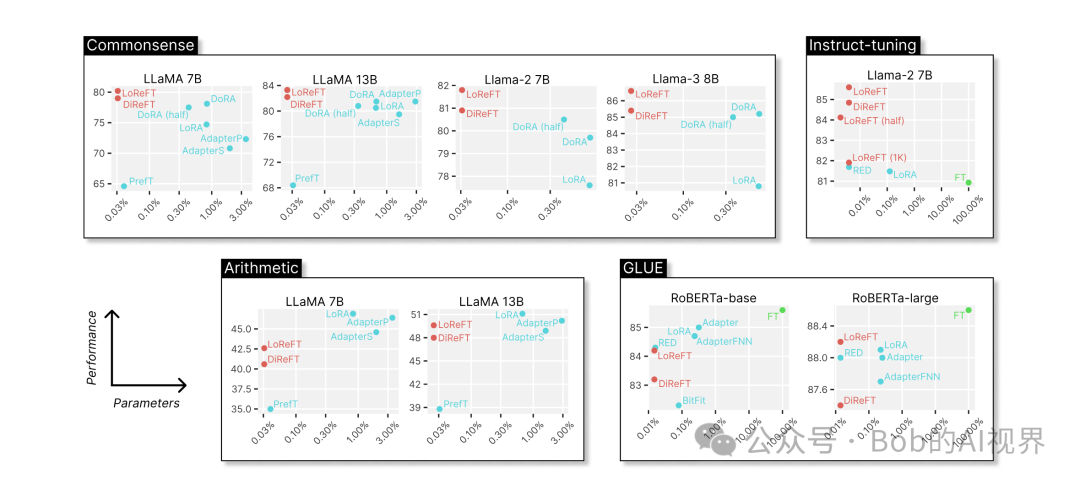
原理
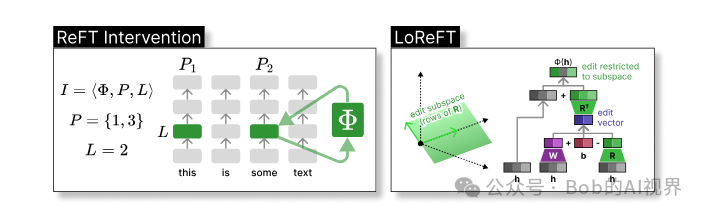
LoReFT 本质上是在一个线性子空间中使用低秩投影矩阵调整隐藏表示。
简化背景: 我们有一个基于 Transformer 架构的语言模型 (LM)。这个 LM 接受一系列的 token(单词或字符)作为输入。首先将每个 token 转换为一个表示,然后通过多层计算参考附近 token 的上下文来优化这些表示。每一步都会生成一组隐藏表示,捕捉每个 token 在序列上下文中的意义。最终,模型使用这些优化后的表示来预测序列中的下一个 token(在自回归 LM 中)或在其词汇空间中预测每个 token 的可能性(在掩码 LM 中)。
ReFT 方法系列改变了模型处理这些隐藏表示的方式,特别是在定义为低秩投影矩阵的特定子空间中进行调整。这有助于提高模型在各种任务中的效率和效果。
干预定义
ReFT 定义了一个干预的概念,它在模型向前传递期间修改隐藏的表示。干预 I 是一个元组 ⟨Φ,P, L⟩,封装了由基于 transformer 的 LM 计算的表示的单个推理时间的干预动作,包含三个参数:
-
• 干预函数 Φ: 用学习到的参数 Φ (Φ) 来表示。
-
• 干预所应用的一组输入位置 P ≤ {1,…,n}。
-
• 对层 L ∈ {1,…,m} 进行干预。
干预的动作如下:
h⁽ˡ⁾ ← (Φ(h_p⁽ˡ⁾) if p ∈ P else h_p⁽ˡ⁾)_{p ∈ 1,…,n}
该干预在前向传播计算完后立即进行,所以会影响到后续层中计算的表示。为了提高计算的效率,也可以将干预的权重进行低秩分解,也就是得到了低秩线性子空间 ReFT (LoReFT)。
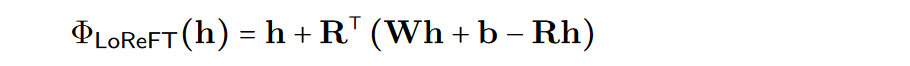
在公式中使用学习到的投影源 Rs = Wh + b。LoReFT 编辑 R 列的 R 维子空间中的表示,来获取从我们的线性投影 Wh + b 中获得的值。
对于生成任务,ReFT 论文使用语言建模的训练目标,重点是在所有输出位置上使用最小化交叉熵损失。
区别与优势
-
• PEFT方法 :例如,LoRA、DoRA 和 prefix-tuning,侧重于修改模型的权重或引入额外的权重矩阵。
-
• ReFT方法 :不直接修改模型的权重;它们会干预模型在向前传递期间计算的隐藏表示。
优势
-
• 参数效率 :ReFT 方法,特别是 LoReFT,在参数效率方面表现出色,通常比现有的 PEFT 方法如 LoRA 更高效(参数效率高15-65倍)。
-
• 性能与效率的平衡 :ReFT 方法在效率和性能之间取得了良好的平衡,通常在多个任务上展现出与 PEFT 方法相当或更好的性能。
-
• 不修改权重 :ReFT 方法不涉及权重更新,而是专注于对隐藏表示的干预,这可以减少对模型结构的修改,从而可能有利于模型的稳定性和可解释性。
-
• 可解释性 :ReFT 方法可能提供比 PEFT 方法更高的可解释性,因为它直接操作模型的内部表示,这可以揭示模型如何执行特定任务。
-
• 兼容性 :ReFT 方法可以作为现有 PEFT 方法的替代品,因为它们是 drop-in replacements,可以很容易地集成到现有的框架中。
-
• 潜在的应用 :ReFT 方法可能适用于多种场景,包括多任务学习、指令调优和跨模态任务,如视觉-语言模型。
使用
可以使用 pyreft 实现 ReFT。
( https://github.com/stanfordnlp/pyreft **** )
论文直达:
( https://arxiv.org/pdf/2404.03592 )
Bob的产品
1.【Bob的AI成长陪伴群】门票🎫99💰/年。
2.【AI+老人回忆录制作】正在运营,有需求 或者 想加入 可微信私聊。
3.【语音咨询】:99💰/小时
群里分享讨论:
🔴AI变现项目、AI前沿技术、NLP知识技术分享、前瞻思考、面试技巧、找工作等
🔴个人IP打造、自媒体副业、向上社交、以及我的日常生活所见所闻,所思所想。
找一群人一起走,慢慢变富。期待和同频朋的友一起蜕变!
扫码加微信,链接不迷路!

本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!