目录
Wise-ft《Robust fine-tuning of zero-shot models》,能解决大模型持续学习灾难性遗忘吗
原创 Bob新视界 Bob的AI视界
大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪
微调框架:
https://github.com/mlfoundations/wise-ft
论文链接
https://arxiv.org/pdf/2109.01903
背景信息:
现有的方法在微调零样本模型时存在两个关键问题。
- 首先,微调模型的 鲁棒性在数据分布发生变化时会有很大差异 ,这种差异受微调过程中的超参数影响显著,但仅通过目标分布上的准确性无法推断出最佳的超参数。
- 其次,更激进的微调(如使用更大的学习率)虽然在目标分布上能带来更大的准确性提升,但在数据分布变化时可能会 导致准确性大幅下降 。
WiSE-FT
论文提出了WiSE-FT(Weight-space Ensembling for Fine-tuning)的微调方法。
● 这个方法的好处:WiSE-FT(Weight-space Ensembling for Fine-tuning)方法通过 组合零样本模型的权重和微调后模型的权重 来解决上述问题。这种方法简单、通用,能够在不增加额外计算成本的情况下,通过几行代码实现。
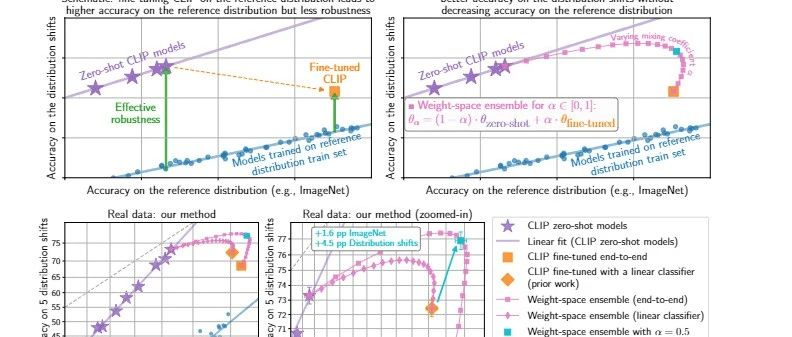
WiSE-FT在多个数据集上展示了比标准微调 更好的准确性 ,尤其是在数据分布变化时, 提高了模型的鲁棒性 。
算法原理与实现:
WiSE-FT具体实现包括以下步骤:
● 微调零样本模型:首先,需要在特定应用数据上微调预训练的零样本模型。这可以通过标准的微调过程来完成,即在新的数据集上训练模型的参数,以适应新的任务。
● 权重组合:微调完成后,将微调后的模型权重与原始零样本模型的权重进行组合。这种组合是通过线性插值实现的,即对两个模型的权重进行加权平均。加权平均的权重α是一个超参数,可以根据具体情况进行调整。
● 权重空间组合:在微调过程中或微调结束后,通过线性插值将两个模型的权重组合起来
WiSE-FT方法的关键在于通过权重空间的组合来利用零样本模型和微调后模型的互补性。这种方法基于两个观察:
首先,零样本模型和微调后模型在权重空间中可以通过一条线性路径连接,在这条路径上模型的准确性保持较高;
其次,这种组合可以利用两个模型的互补预测能力。
实验结果
通过实验,作者发现WiSE-FT在多种数据分布变化下都能提高模型的鲁棒性,并且在多个数据集上比标准微调方法有更好的准确性。此外,WiSE- FT还在低数据量的情况下显示出性能提升,这表明即使在微调数据稀缺的情况下,该方法也能提供改进。
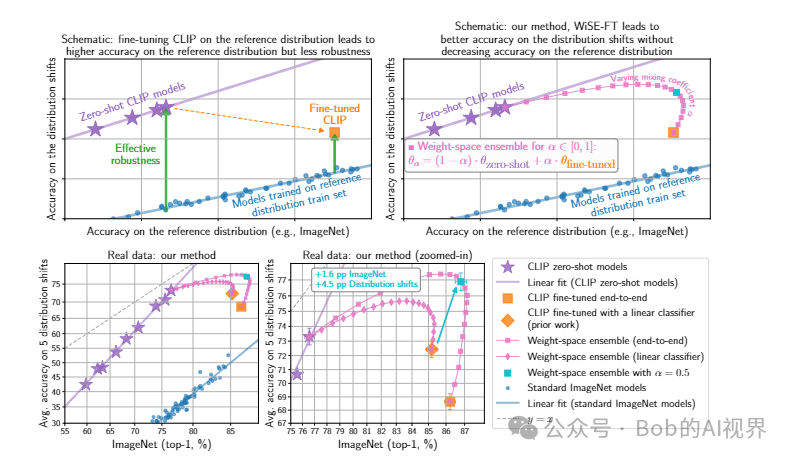
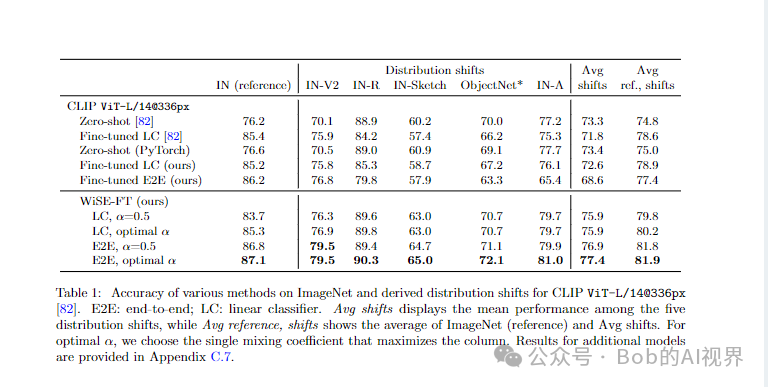
实验证明 WiSE-FT 提高了 Radford 等人研究的五个 ImageNet 分布偏移上微调 CLIP 模型的准确性。 [82],同时保持或提高 ImageNet 的准确性。
具体而言,相对于微调解决方案,WiSE-FT (α= 0.5) 将分布偏移下的性能提高了 3.5、6.2、1.7、2.1、9.0 和 23.2 pp,同时将参考分布的性能降低最多 0.3 pp(准确度参考分布通常会得到改善)。
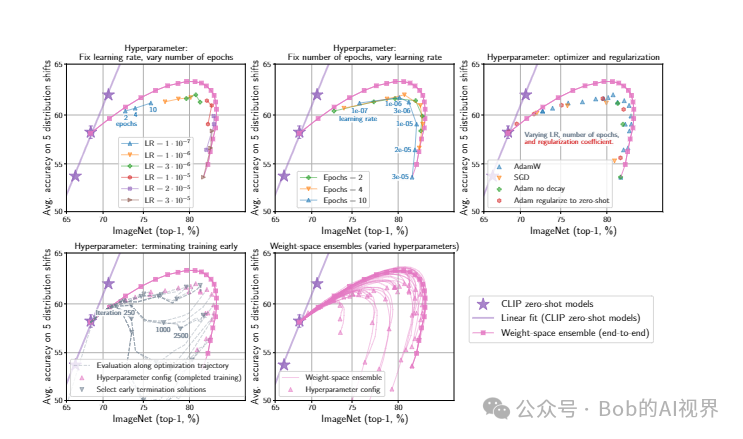
即使超参数发生微小变化,微调模型的稳健性也会发生很大变化。应用 WiSE-FT 可以解决这种脆弱性,并且可以消除参考分布和移位分布的准确性之间的权衡。
总的来说,WiSE-FT提供了一种简单有效的微调策略,可以在不增加额外计算成本的情况下提高模型的性能和鲁棒性 。
Bob 的产品
1.【Bob 的 AI 成长陪伴群】门票 🎫99💰/年。
2.【AI+老人回忆录制作】正在运营,有需求 或者 想加入 可微信私聊。
3.【语音咨询】:99💰/小时
群里分享讨论:
🔴AI 变现项目、AI 前沿技术、NLP 知识技术分享、前瞻思考、面试技巧、找工作等
🔴 个人 IP 打造、自媒体副业、向上社交、以及我的日常生活所见所闻,所思所想。
找一群人一起走,慢慢变富。期待和同频 朋的 友一起蜕变!
扫码加微信,链接不迷路!

本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!