目录

论文参考:
GPT1—language_understanding_paper
GPT2—language_models_are_unsupervised_multitask_learners
GPT-3 Language Models are Few-Shot Learners
Generative Pre-trained Transformer(GPT)系列是由 OpenAI 提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的 NLP 任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,问答等,而完成这些任务甚至 并不需要有监督学习进行模型微调 。
本文梳理了 GPT 系列文章中介绍的的关键技术,包括:
- GPT-1 的解码器、微调、输入形式;
- GPT-2 的 Zero-shot 和 Prompt;
- GPT-3 的 Few-shot;
- Instruct GPT 如何通过基于人类反馈的强化学习生成有帮助的和安全的文本。
GPT1:
作者提出问题:
1.用什么样的优化函数
2.怎么把模型迁移到所有子任务上
预训练
无监督学习
预测一个联合文本出现的概率,通过最大化这个概率来训练

GPT-1 使用的是一个标准的语言模型,在训练时使用 Transformer 的 解码器 。在解码器中,会将一个词之后的文本进行掩码,因此解码器只能看到一个词之前的文本,不能看到之后的文本。
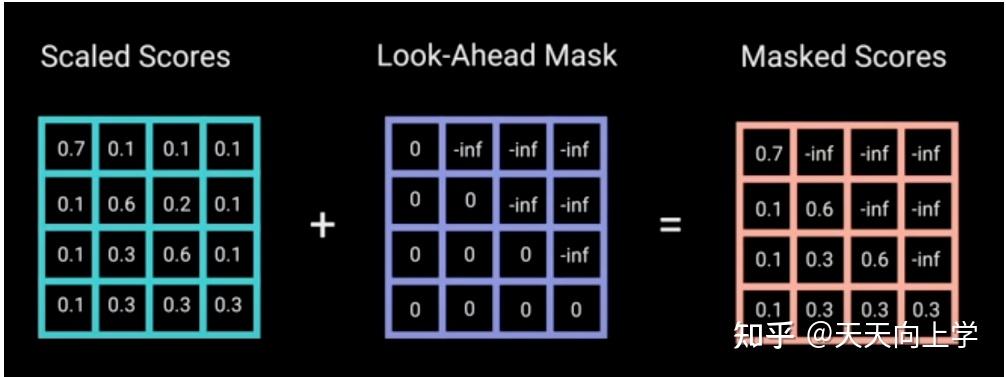
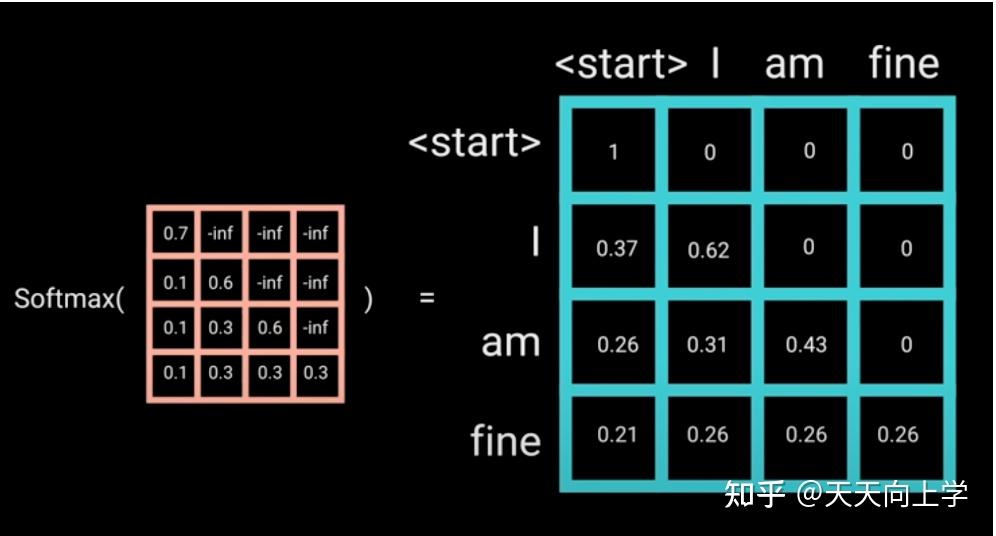
训练 GPT 时,模型只能看到前文来预测后文,而 BERT 可以看到上下文来预测中间部分。GPT 得到的输入信息更少,这就导致训练 GPT 比训练 BERT 难很多。
微调:
第一个目标函数是在预测下一个词,给定一个序列,预测下一个词:
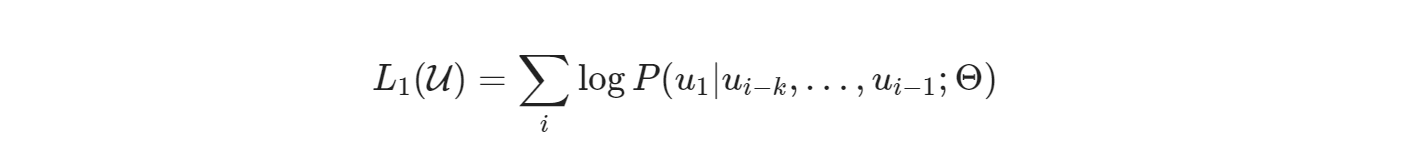
第二个目标函数是在做多分类任务,给定所有序列,预测它的标签:
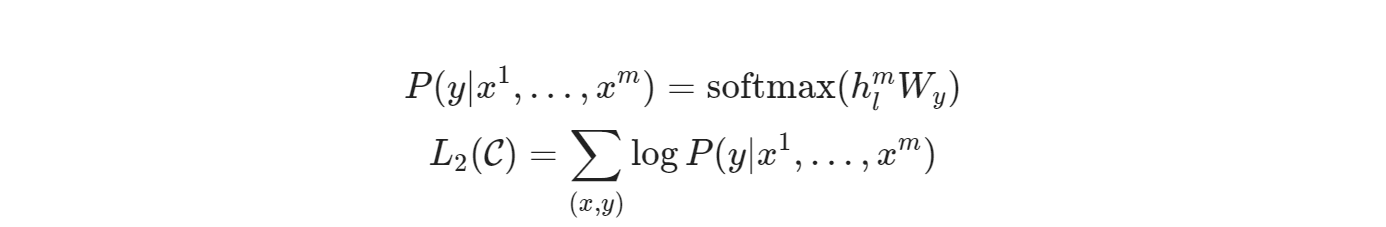
文章中作者提到,把这两个目标函数结合一起训练,效果会更好,可以提高模型的泛化性,最终优化成的函数:
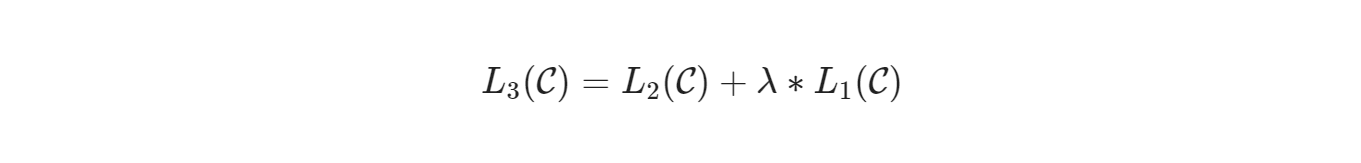
构造不同输入来适应下游子任务:
作者在最开始有提到怎么去把模型迁移到不同的子任务的问题,也是此文的一个买点
此处就有解释,就是说把输入通过加入一些字符,比如等,去及微调,这样在预测时,模型就可以分辨出,这是属于哪类任务范畴,比如图片中的相似度,多分类等。
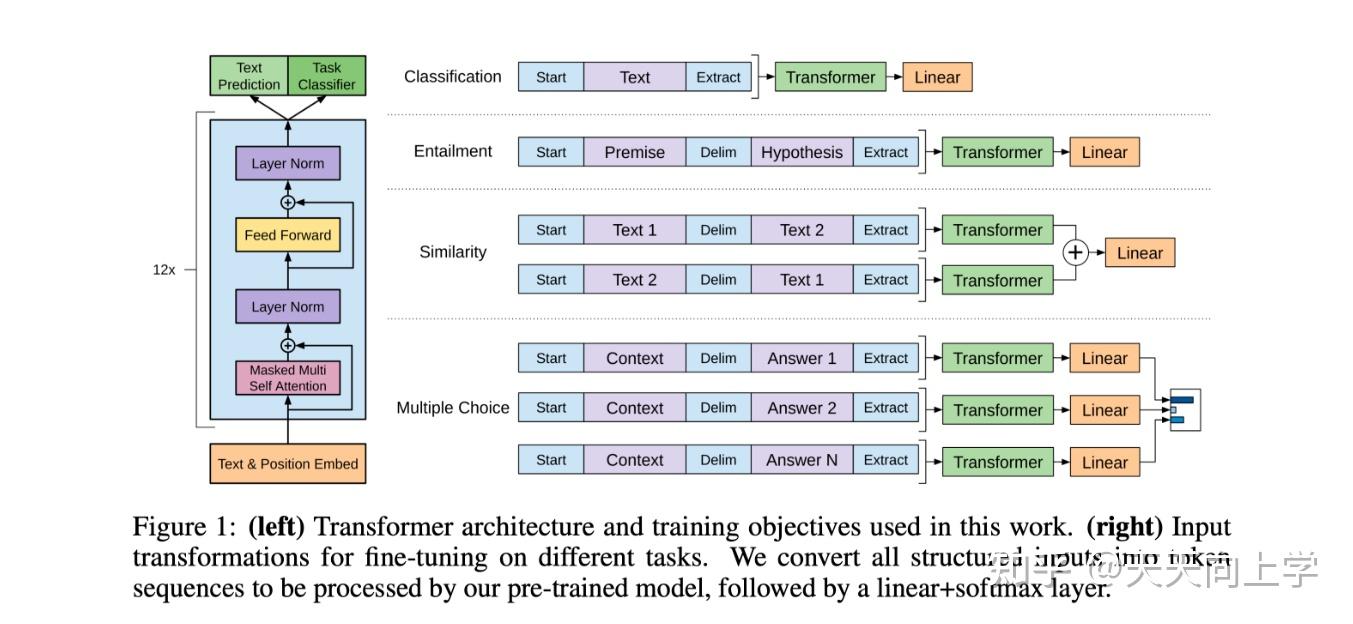
至此GPT1大部分重点已经讲完了,详细可以看哔哩哔哩李沐老师的视频。
GPT2
GPT1,Bert模型存在两个个问题:
- 对每一个下游任务需要重新训练
- 收集有标号的数据
zero-shot:
相较于GPT1,GPT2的参数量增加,且提出了zero-shot,可以简单理解为使用大量数据集,提高模型泛化性,以适应下游任务。
zero-shot: 在做到下游任务的时候,不需要下游任务的任何标注信息,那么也不需要去重新训练已经预训练好的模型。这样子的好处是我只要训练好一个模型,在任何地方都可以用。
GPT3
下游任务:
相较于GPT-2,GPT-3在下游方面又有了一些改进,它利用少量样本去学习,也就是 Few-shot。
few-shot:
指在下游任务中给出少量样本让模型学习,但不进行模型参数的更新
因为GPT-3模型参数量太大,重新训练困难
例如:把英文翻译成中文
few-shot: hello —> 你好
你可以简单地理解为**”举一反三“**或者 prompt 提示。在输入问题时,告诉它一些例子。具体信息可以看下面的图片。

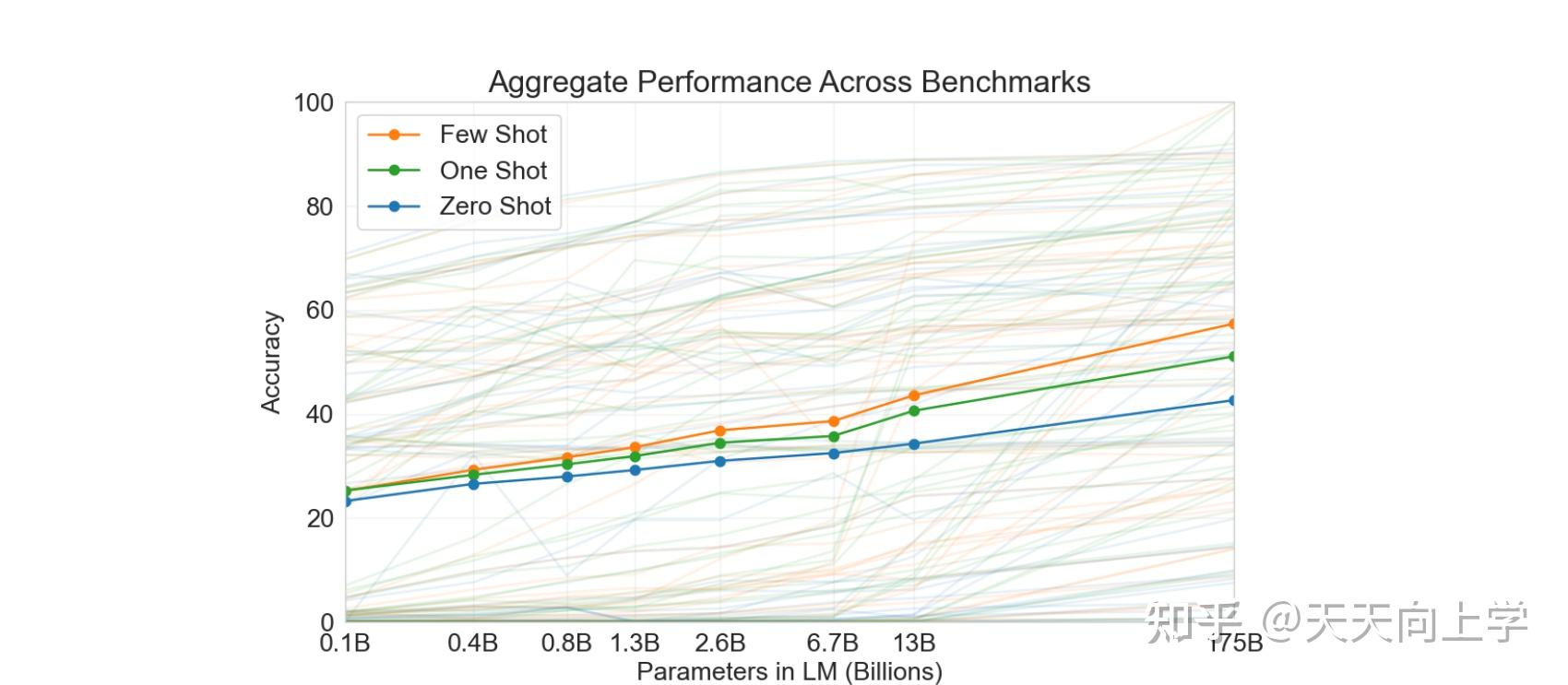
实验结果如下:
可见Few Shot 的效果还是很可观的
数据处理:
由于GPT3的数据量需要很大来提高泛化性。
但是有些数据质量不佳,有很大噪音,影响模型性能。
所以作者使用一些低质量数据和高质量数据训练了一个模型,最后使用它来区分高质量数据
**使用lsh算法,来区分相似度高的数据 **
本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!