目录
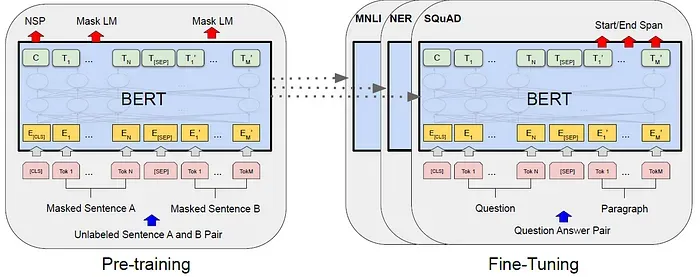
BERT:深度双向转换器的预训练用于语言理解,由Google AI Language提出的BERT,发表于2019年NAACL,并超过31000次引用
BERT,即双向编码器变换(Bidirectional Encoder Representations from Transformers),通过在所有层次上联合条件地对未标记文本进行预训练,从而生成深度的双向表示。 这个预训练的BERT模型可以通过仅添加一个额外的输出层进行微调,创建出在各种任务上具有最先进性能的模型,如问答和语言推理,而无需进行大量的特定任务架构修改。 这是一种自监督学习,其中预设任务是语言模型学习,而具体任务则是通过微调进行的下游任务。
1. BERT: Bidirectional Encoder Representations from Transformers
1.1. BERT的训练步骤
BERT框架中有两个步骤:预训练和微调。 在pre-training期间,模型在未标记的数据上进行训练。 对于fine-tuning,BERT模型首先使用预训练的参数进行初始化,然后使用来自下游任务的标记数据进行微调。
1.2. BERT模型架构
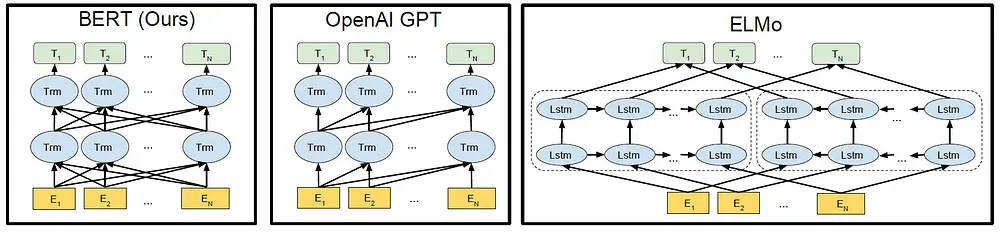 BERT使用了一个双向的Transformer。 OpenAI的GPT使用了一个由左到右的Transformer。ELMo则使用了独立训练的由左到右和由右到左的LSTM的串接。
BERT使用了一个双向的Transformer。 OpenAI的GPT使用了一个由左到右的Transformer。ELMo则使用了独立训练的由左到右和由右到左的LSTM的串接。
BERT的模型架构是基于Transformer的多层双向编码器。实现方式与原始版本几乎相同。 层数(即Transformer块)的数量用L表示,hidden size用H表示,self-attention heads用A表示。
有两种模型大小可供评估:
BERTBASE(L=12,H=768,A=12,总参数=110M),与OpenAI的GPT具有相同的模型大小,用于比较目的。
BERT的Transformer使用双向self-attention,而GPT的Transformer使用了限制的self-attention,其中每个token只能关注其左侧的内容。
BERTLARGE(L=24,H=1024,A=16,总参数=340M)。
1.3. Input Representation
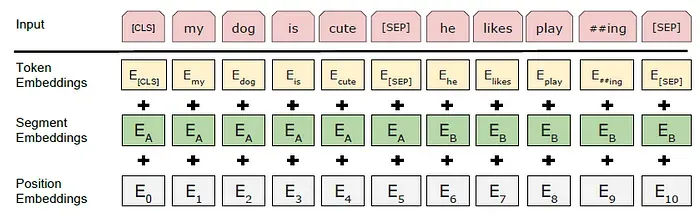 BERT input representation
为了使BERT能够处理各种下游任务,输入表示能够明确表示单个句子和一对句子(例如,<Question, Answer>)的序列。
使用具有30,000个令牌词汇的WordPiece嵌入(Wu et al.,2016)。
每个序列的第一个令牌始终是一个特殊的分类token([CLS])。
使用一个特殊的token([SEP])进行分隔。
对于给定的token,其输入表示是通过将相应的token、segment和position embeddings相加来构造的。如上图所示,这种构造的可视化。
BERT input representation
为了使BERT能够处理各种下游任务,输入表示能够明确表示单个句子和一对句子(例如,<Question, Answer>)的序列。
使用具有30,000个令牌词汇的WordPiece嵌入(Wu et al.,2016)。
每个序列的第一个令牌始终是一个特殊的分类token([CLS])。
使用一个特殊的token([SEP])进行分隔。
对于给定的token,其输入表示是通过将相应的token、segment和position embeddings相加来构造的。如上图所示,这种构造的可视化。
2. BERT的预训练
2.1. Masked LM (MLM)
输入token的一部分会被随机遮罩,然后对这些屏蔽的token进行预测。
在每个序列中,随机屏蔽15%的WordPiece token。
只预测被屏蔽的词语,而不是重构整个输入。
如果选择了第i个token,则将第i个token替换为(1)有80%的机率将该token替换为[MASK] token(2)10%的机率替换为随机token(3)10%的机率保持不变。然后,Ti将用于使用cross entropy loss预测原始token。
2.2. Next Sentence Prediction (NSP)
下游任务,如问答(QA)和自然语言推理(NLI),是基于理解两个句子之间的关系,而这并不是语言建模直接捕捉的。首先进行了二元化的下一句预测任务的预训练,这可以从任何单语语料库轻松生成。 具体来说,在选择每个预训练示例的句子A和B时,有50%的机率B是实际跟在A后面的下一句(标记为IsNext),另外50%的机率B是来自语料库的随机句子(标记为NotNext)。
2.3. Pretraining Dataset
对于预训练语料库,使用了BooksCorpus(800M字)(Zhu et al., 2015)和English Wikipedia(2,500M字)。 对于维基百科,仅提取文本段落,忽略列表、表格和标题。
3. Fine-Tuning BERT
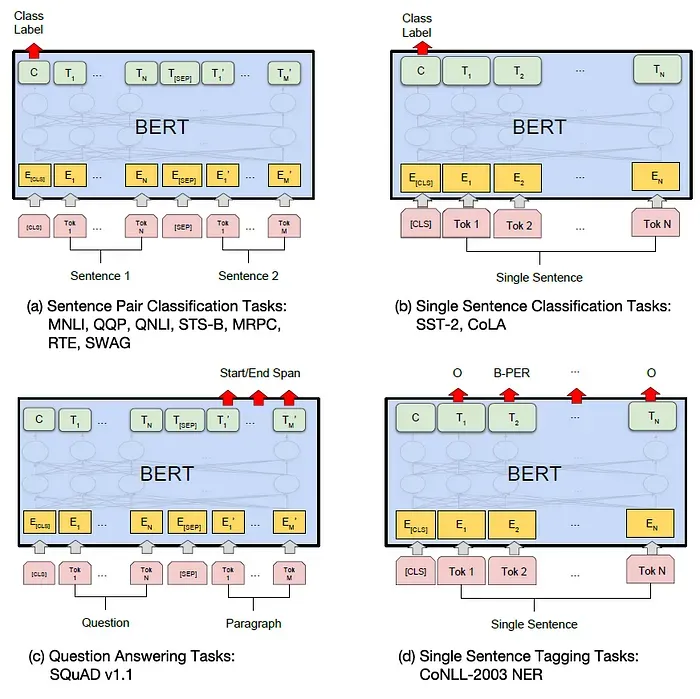 Illustrations of Fine-tuning BERT on Different Tasks
对于每个任务,任务特定的输入和输出只需插入到BERT中,并且所有参数都进行端到端的微调。
Illustrations of Fine-tuning BERT on Different Tasks
对于每个任务,任务特定的输入和输出只需插入到BERT中,并且所有参数都进行端到端的微调。
在输入端,预训练的句子A和句子B对应于(1)重述中的句子对,(2)蕴含中的假设-前提对(3)问答中的问题-段落对,以及(4)文本分类或序列标记中的退化文本-Ø对。 在输出端,token表示被喂入一个输出层,用于token级任务,例如序列标记或问答,而[CLS]表示则被喂入一个输出层,用于分类,例如蕴涵或情感分析。 相较于预训练,微调的成本相对较低。在一个单一的Cloud TPU上,所有论文中的结果最多只需1小时,或在GPU上几小时就能复制。
4. SOTA Comparison
4.1. GLUE
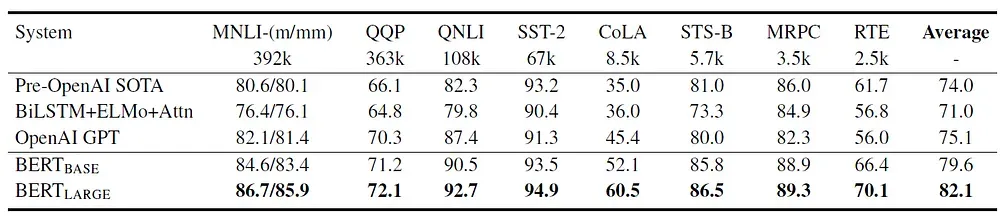 GLUE通过评估服务器进行测试的结果
在微调过程中,只引入了分类层的权重W,其中K是标签的数量。使用标准的分类损失函数C 和W,即log(softmax(CW^T))。
BERTBASE和BERTLARGE在所有任务上均大幅优于先前的顶尖系统,分别相对于先前的最新技术提高了4.5%和7.0%的平均准确率。
GLUE通过评估服务器进行测试的结果
在微调过程中,只引入了分类层的权重W,其中K是标签的数量。使用标准的分类损失函数C 和W,即log(softmax(CW^T))。
BERTBASE和BERTLARGE在所有任务上均大幅优于先前的顶尖系统,分别相对于先前的最新技术提高了4.5%和7.0%的平均准确率。
需要注意的是,BERTBASE和OpenAI的GPT在模型架构上几乎相同,除了attention masking。 对于最大且报告最广泛的GLUE任务MNLI而言,BERT在绝对准确率上提高了4.6%。根据GLUE的官方排行榜,BERTLARGE的得分为80.5,而OpenAI的GPT在撰写本文时的得分为72.8。
4.2. SQuAD 1.1.
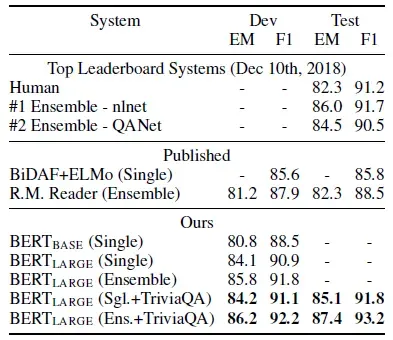 SQuAD 1.1的结果。 BERT合奏是使用不同的预训练检查点和微调种子的7个系统
斯坦福问答数据集(SQuAD v1.1)是一个由10万个众包问题/答案对组成的集合。
输入的问题和段落被表示为一个单一的打包序列,其中问题使用A嵌入,段落使用B嵌入。
在微调过程中,只引入了开始向量S和结束向量E。
词i是答案范围开始的机率,计算方式是将Ti和S进行内积,然后对段落中的所有词进行softmax:
SQuAD 1.1的结果。 BERT合奏是使用不同的预训练检查点和微调种子的7个系统
斯坦福问答数据集(SQuAD v1.1)是一个由10万个众包问题/答案对组成的集合。
输入的问题和段落被表示为一个单一的打包序列,其中问题使用A嵌入,段落使用B嵌入。
在微调过程中,只引入了开始向量S和结束向量E。
词i是答案范围开始的机率,计算方式是将Ti和S进行内积,然后对段落中的所有词进行softmax:
结束的答案范围也是类似的。 从位置i到位置j的候选范围的得分定义如下:
使用得分最高的范围j≥i,作为预测。 最佳的BERT在集成中比领先的系统提高了+1.5 F1,在单一系统中提高了+1.3 F1。事实上,单一BERT模型在F1分数方面超越了顶级集成系统。
4.3. SQuAD 2.0
SQuAD 2.0的结果 SQuAD 2.0任务扩展了SQuAD 1.1的问题定义,允许提供的段落中可能不存在简短答案,使问题更现实
相较于先前最佳系统,观察到了+5.1的F1改进。
4.4. SWAG
SWAG开发和测试的准确性(使用100个样本测量人类表现) Situations With Adversarial Generations (SWAG)数据集包含11.3万个句子对完成示例,用于评估基于常识推理的推断。 给定一个句子,任务是在四个选择中选择最合理的继续。 在SWAG数据集上进行微调时,构造了四个输入序列,每个序列都包含给定句子(句子A)和可能的继续(句子B)的串联。 BERTLARGE比作者的baseline ESIM+ELMo系统提高了+27.1%,比OpenAI的GPT提高了8.3%。
5. Ablation Study
5.1. Effect of Pre-Training Tasks
使用BERTBASE架构的消融预训练任务 “No NSP”是在没有下一句预测任务的情况下进行的训练。 “LTR&No NSP”被训练为一个从左到右的语言模型,没有下一句预测,就像OpenAI的GPT一样。 “+ BiLSTM”在微调期间在“LTR + No NSP”模型上添加了一个随机初始化的双向LSTM。 在QNLI,MNLI和SQuAD 1.1上,去除NSP会严重影响性能。 LTR模型在所有任务上的性能都比MLM模型差,MRPC和SQuAD的性能下降较大。
5.2. Effect of Model Size
来自5个随机重启的对GLUE进行微调的平均开发集准确性 更大的模型在所有四个数据集上都带来严格的准确度提升,即使对于MRPC,它只有3,600个标记的训练示例,并且与预训练任务差异很大。 这是第一个令人信服地证明,将模型扩展到极端大小也会在非常小规模的任务上实现显著的改进,前提是模型已经得到足够的预训练。
5.3. Feature-based Approach with BERT
CoNLL-2003命名实体识别结果 到目前为止,所有的BERT结果都使用了微调方法,即在预训练模型上添加了一个简单的分类层,并且在下游任务上联合微调所有参数。 然而,这里评估了基于特征的方法,即从预训练模型中提取固定特征,有两个原因: 首先,并非所有任务都可以通过Transformer编码器架构轻松表示。 其次,主要的计算优势可以被预先计算。 特征为基础的方法是通过从BERT的一个或多个层中提取激活,而不对BERT的任何参数进行微调来应用。 这些embeddings内容被用作分类层之前的一个随机初始化的双层768维双向LSTM的输入。 表现最佳的方法是将预训练Transformer的前四个隐藏层的token表示串接在一起,与微调整个模型相比仅差0.3的F1 Score。
这表明BERT对微调和基于特征的方法都是有效的。
本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!