目录
背景:
one-hot编码有大量缺点
高维稀疏表示:One-hot编码将每个词表示为一个高维稀疏向量,向量的维度等于词汇表的大小。对于大规模的词汇表,会导致非常高维的表示,造成存储和计算的开销增加。
无法捕捉词之间的语义关系:One-hot编码中,每个词的向量是独立的,没有考虑词之间的语义关系。因此,无法直接通过向量计算来衡量词之间的相似度或语义距离。
维度灾难:随着词汇表的增大,One-hot编码的维度也会增加,这可能导致维度灾难问题。高维度的表示会增加模型的复杂度和计算开销,并且在有限的数据情况下容易过拟合。
无法处理未见过的词:One-hot编码的词汇表是固定的,如果遇到未见过的词,无法进行有效的表示。这在现实世界的文本数据中很常见,特别是在处理新闻、社交媒体等动态数据时。
Word2vec介绍:
Word2vec是一类神经网络模型
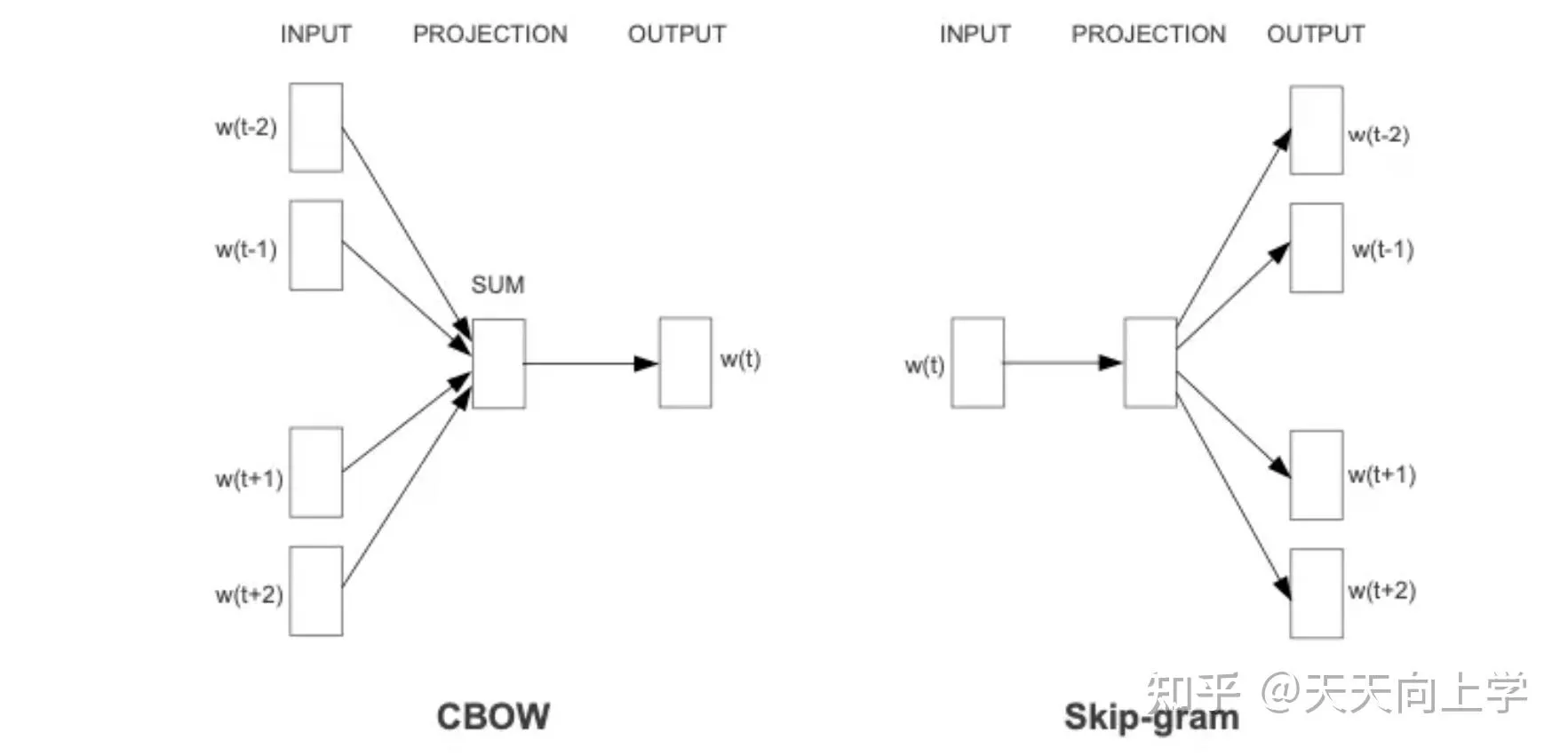
类型分为CBOW与Skip-gram
CBOW
给定词的上下文,预测该词。一个老师告诉多个学生,Q矩阵怎么变
Skip-gram
给该词,预测该词的上下文。多个老师告诉一个学生, Q矩阵怎么变
Word2vec词向量的处理对象是单词。它将单词转换为连续向量表示,可以用来表示单词之间的语义关联性。 以下是一个示例,展示了一些单词及其对应的Word2vec词向量:
"apple":[0.5, 0.3, -0.2, 0.1] "banana":[0.2, 0.6, -0.3, 0.4] "orange":[0.4, 0.1, -0.5, 0.2]
这些向量表示了每个单词在向量空间中的位置,可以用来计算它们之间的相似性或进行其他语义相关的任务。 NNLM和Word2Vec的区别
NNNL --》 重点是预测下一词 Word2Vec--》 CBOW 和 Skip-gram 的两种架构的重点都是得到一个Q矩阵
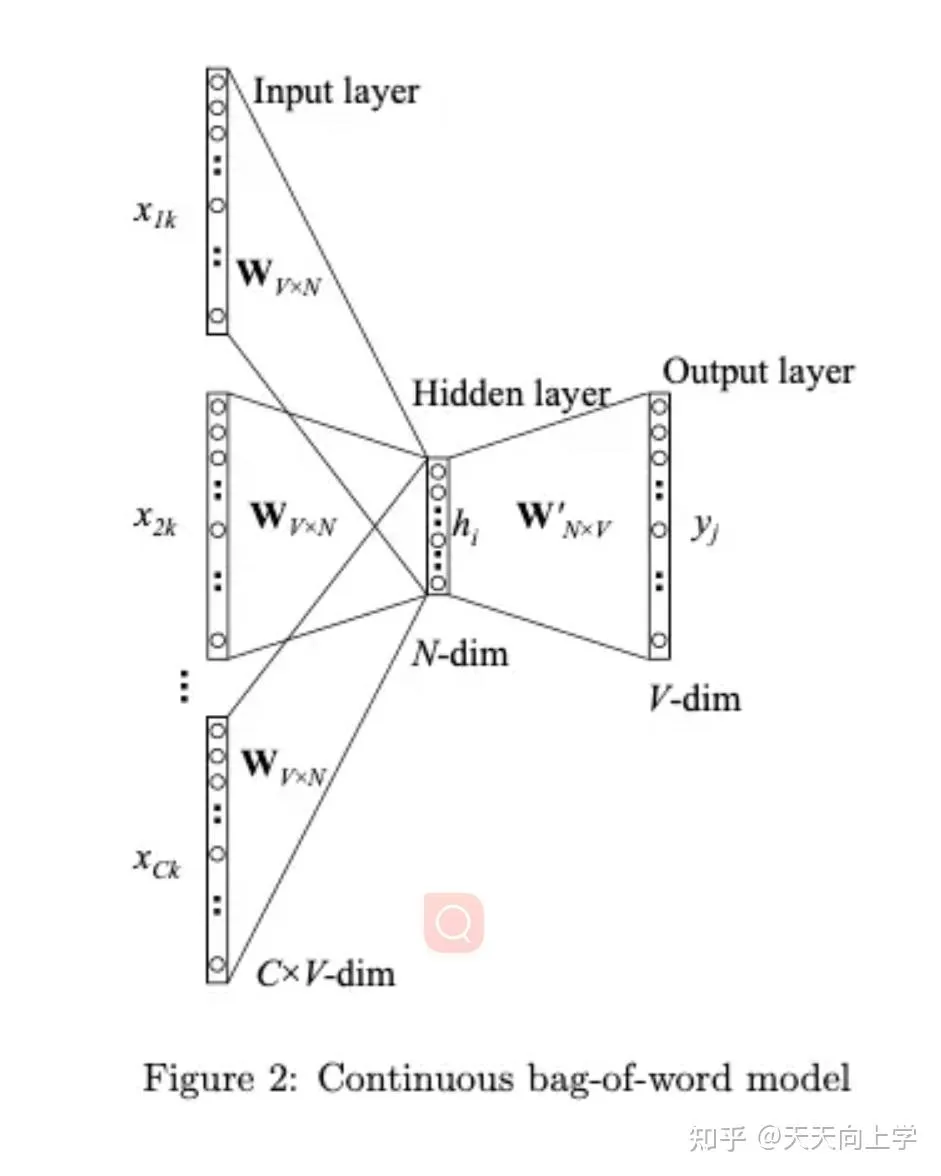
通过反向传播更新Q矩阵。softmax(w1 (xQ) +b1)
本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!