目录

大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪
LLama.cpp项目,在cpu上部署模型
llama.cpp原生支持大规模语言模型的量化,并且一如既往地保持了灵活性。
在高层次上,llama.cpp所支持的所有量化都是权重量化(weight quantization):模型参数被量化为低位(bit)数,在推理过程中,它们会被反量化(dequantize)并用于计算。
-
纯粹的C/C++实现,没有外部依赖
-
支持广泛的硬件:
-
x86_64 CPU的AVX、AVX2和AVX512支持
-
通过Metal和Accelerate支持Apple Silicon(CPU和GPU)
-
NVIDIA GPU(通过CUDA)、AMD GPU(通过hipBLAS)、Intel GPU(通过SYCL)、昇腾NPU(通过CANN)和摩尔线程GPU(通过MUSA)
-
GPU的Vulkan后端
-
-
多种量化方案以加快推理速度并减少内存占用
-
CPU+GPU混合推理,以加速超过总VRAM容量的模型
它就像 Python 框架 torch+transformers 或 torch+vllm 的组合,但用的是 C++。
GitHub link:
https://github.com/ggerganov/llama.cpp
中文文档:
https://qwen.readthedocs.io/zh-cn/latest/run_locally/llama.cpp.html#conversation-mode
简单部署
- 获取
llama-cli程序
plaintextgit clone https://github.com/ggerganov/llama.cpp cd llama.cpp
plaintextmake llama-cli
获取 GGUF模型
直接从model scope下载:
pythonimport os
import subprocess
def download_model(model_name:str,model_file:str='',dir:str=''):
path=dir+model_name.split('/')[-1]
try:
subprocess.run(['modelscope', 'download', '--model',model_name,model_file,'--local_dir',path], check=True)
print(f"Model '{model_name}' downloaded successfully.")
except subprocess.CalledProcessError as e:
print(f"Error downloading model '{model_name}': {e}")
pythondownload_model("Qwen/Qwen2-0.5B-Instruct-GGUF","qwen2-0_5b-instruct-fp16.gguf")
运行模型
python./llama-cli -m /home/phb/phb/models/Qwen2-0.5B-Instruct-GGUF/qwen2-0_5b-instruct-fp16.gguf -co -cnv -p "You are a helpful assistant." -fa -ngl 80 -n 512
-m 或 –model:
显然,这是模型路径。
-co 或 –color:
为输出着色以区分提示词、用户输入和生成的文本。提示文本为深黄色;用户文本为绿色;生成的文本为白色;错误文本为红色。
-cnv 或 –conversation:
在对话模式下运行。程序将相应地应用聊天模板。
-p 或 –prompt:
在对话模式下,它作为系统提示。
-fa 或 –flash-attn:
如果程序编译时支持 GPU,则启用Flash Attention注意力实现。
-ngl 或 –n-gpu-layers:
如果程序编译时支持 GPU,则将这么多层分配给 GPU 进行计算。
-n 或 –predict:
要预测的token数量。
自定义模型运行
HF格式转GGUF
使用我已经lora微调+合并的模型文件转GGUF
https://qwen.readthedocs.io/zh-cn/latest/quantization/llama.cpp.html
pythonpython convert_hf_to_gguf.py /home/phb/phb/merge_model/sft-Qwen2-0.5B-Instruct
--outfile /home/phb/phb/GGUF_model/Qwen2-0.5B-instruct-f16.gguf
这个命令默认会加载保存为16位
但是建议使用fp32。无论是直接加载还是用于作为量化的起点都很好。
pythonpython convert_hf_to_gguf.py /home/phb/phb/merge_model/sft-Qwen2-0.5B-Instruct --outtype f32
--outfile /home/phb/phb/GGUF_model/Qwen2-0.5B-instruct-f32.gguf
量化GGUF
python./llama-quantize /home/phb/phb/GGUF_model/Qwen2-0.5B-instruct-f32.gguf /home/phb/phb/GGUF_model/Qwen2-0.5B-instruct-q8_0.gguf Q8_0
支持的参数:
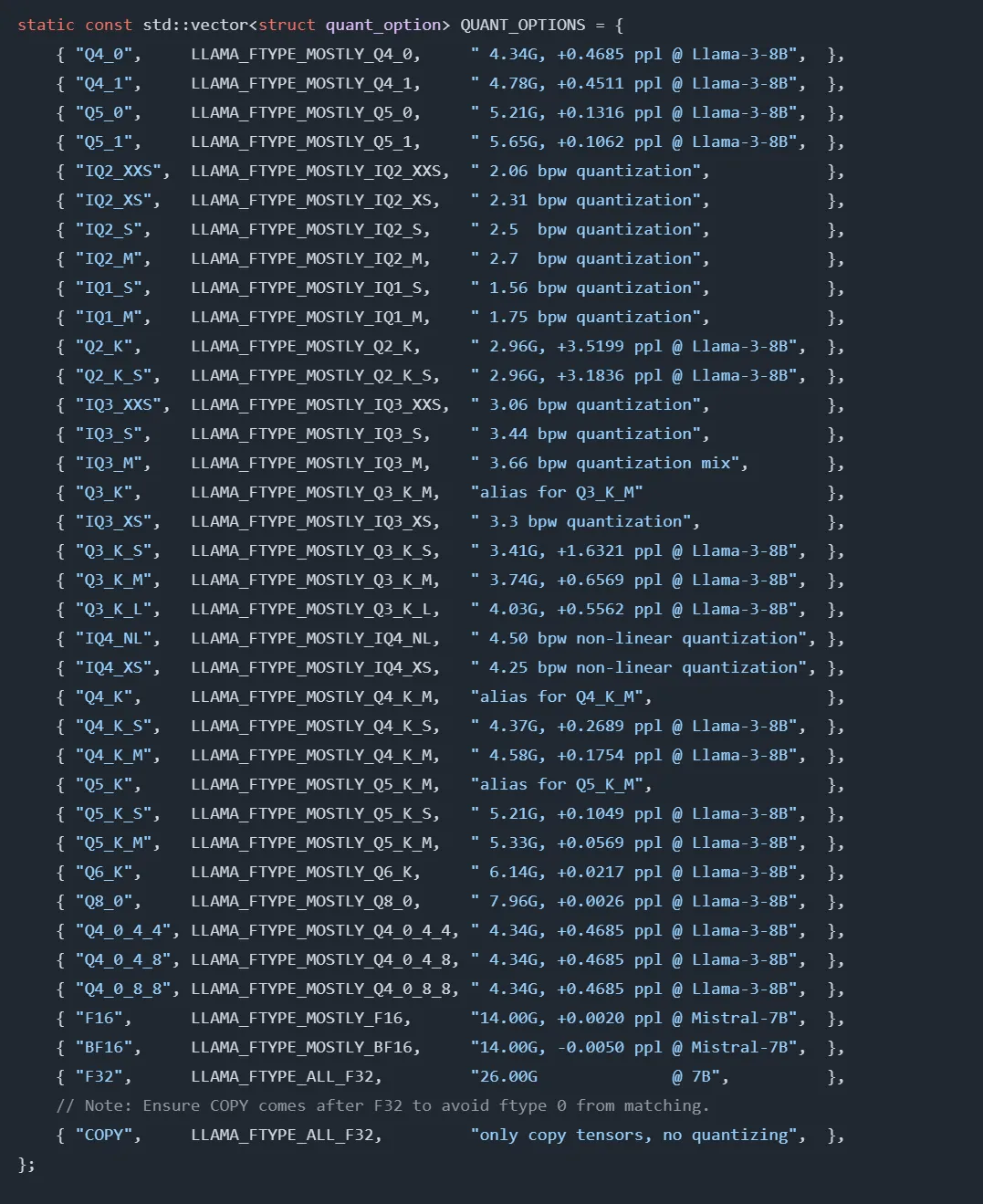 启动模型推理
启动模型推理
python./llama-cli -m /home/phb/phb/GGUF_model/Qwen2-0.5B-instruct-f16.gguf -co -cnv -p "You are a helpful assistant." -fa -ngl 80 -n 512
Bob 的产品
1.【Bob 的 AI 成长陪伴群】门票 🎫99💰/年。
2.【AI+老人回忆录制作】正在运营,有需求 或者 想加入 可微信私聊。
3.【语音咨询】:99💰/小时
群里分享讨论:
🔴AI 变现项目、AI 前沿技术、NLP 知识技术分享、前瞻思考、面试技巧、找工作等
🔴 个人 IP 打造、自媒体副业、向上社交、以及我的日常生活所见所闻,所思所想。
找一群人一起走,慢慢变富。期待和同频 朋的 友一起蜕变!
扫码加微信,链接不迷路!

本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!