目录

大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪
transformer 起初采用的是绝对位置编码,但随着用户对大模型上下文和效率的追求,行业在不断改进,绝对位置编码依然淘汰。了解最新的位置编码算法对于认识当前大模型有很好的帮助。
位置编码论文
相对位置编码:https://arxiv.org/abs/1803.02155
ALiBi位置编码:https://arxiv.org/abs/2108.12409
Sandwich位置编码:https://arxiv.org/abs/2106.12598
Relation-aware Self-attention
关系感知的自注意力
Relation-aware Self-attention的工作。该工作最初是为了解决Transformer的Self-attention模块中无法编码位置信息的问题,在机器翻译任务上取得了很好的结果。
Relation-aware Self-attention实际上就是在计算任意两个token i和j的Self-attention时,考虑他们的先验关系。

而且作者假设超过一定距离后的相对位置信息将不那么重要(比如,第一个token和第500个token之间的相对位置信息肯定没有第一个token和第二token之间的相对位置信息重要),所以这里作者设置了一个阈值k,即只考虑相对位置偏差在k范围内的位置信息。
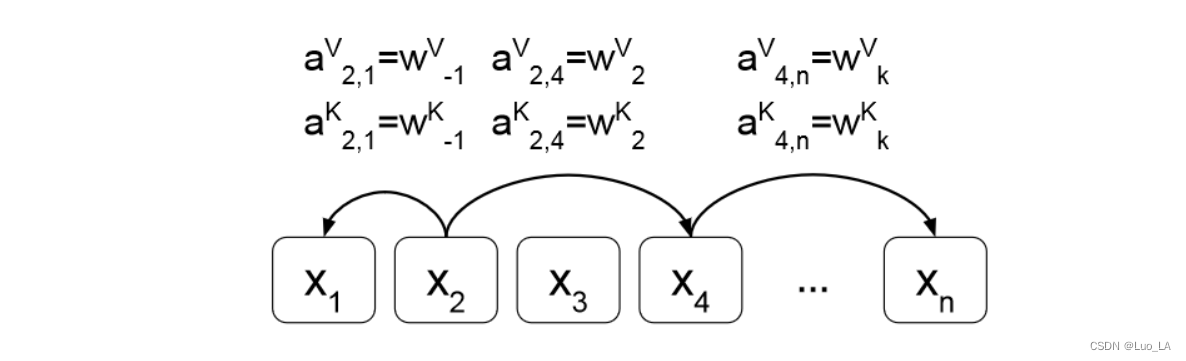
并且 是需要学习的
RoPE
我们可以思考一下,如何表达出两个张量之间的匹配度。如attention的论文所表示的,使用q k的内积再做softmax来表示。而为了加入位置信息,使用sin/cos的绝对位置编码,加入张量以影响内及大小/匹配度。但是这样某种意义上来说并没有什么意义,还会改变语义信息。
但改变内积还有一种方法,就是保证原有q k的值不变,改变张良之间的夹角。 夹角越小,匹配度越高。
这时候假设输入序列为2维,引入旋转矩阵计算q(旋转mθ),同样也可以计算k(nθ)。那么从相对的角度上来说,某一个向量旋转了(mθ-nθ)。
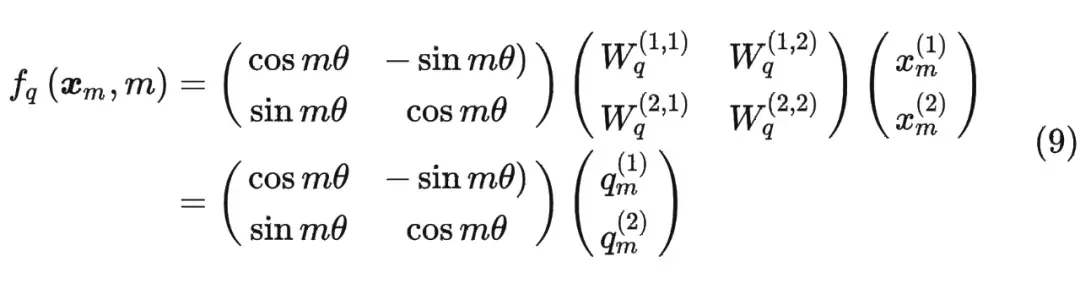
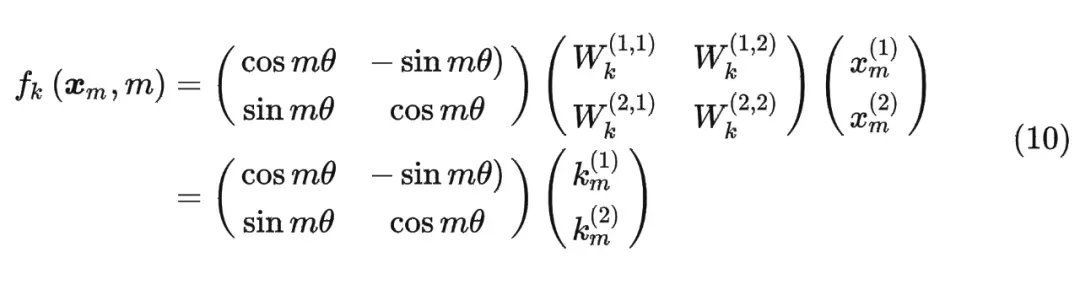
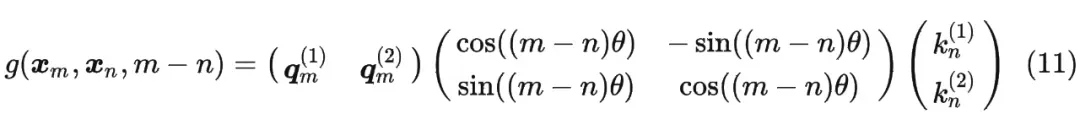
内积满足线性叠加性,因此任意偶数维的 RoPE,我们都可以表示为二维情形的拼接,即

但是这种矩阵计算不高效,浪费算力,我们做这种修改

ALiBi
背景与挑战
当大模型在训练和预测时的输入长度不一致时,模型的泛化能力会下降。若外推能力不佳,大模型在处理长文本或多轮对话时的效果就会受到限制。正弦位置编码的外推能力比较弱,RoPE(Rotary Positional Embedding,旋转式位置嵌入)的外推能力有一定提高但仍然有限。
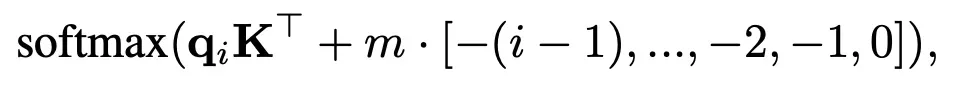
技术
Alibi算法给attention score添加了一个预设的线性偏置矩阵,如图1所示,使模型能够理解输入之间的相对位置关系。由于位置信息直接作用于attention score上,位置差异性被突出,使模型具有较强的外推能力。


sandwich编码
Sandwich将ALiBi的线性bias改为正弦编码的内积pm*pn,上述编码也是对于正余弦三角式的一种改进。
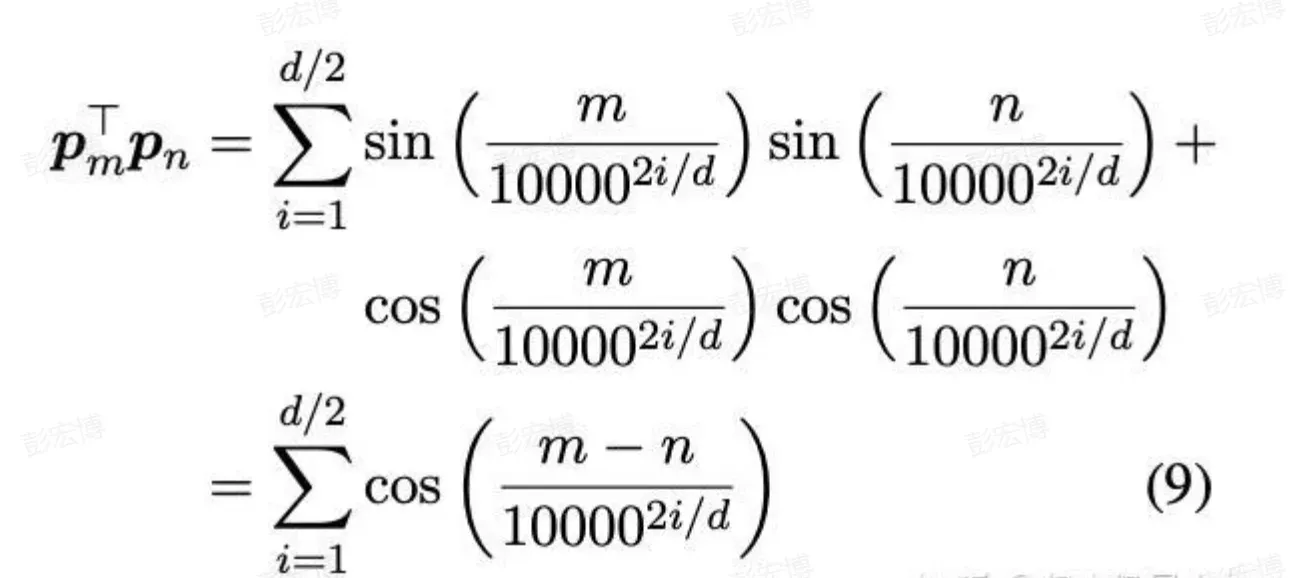
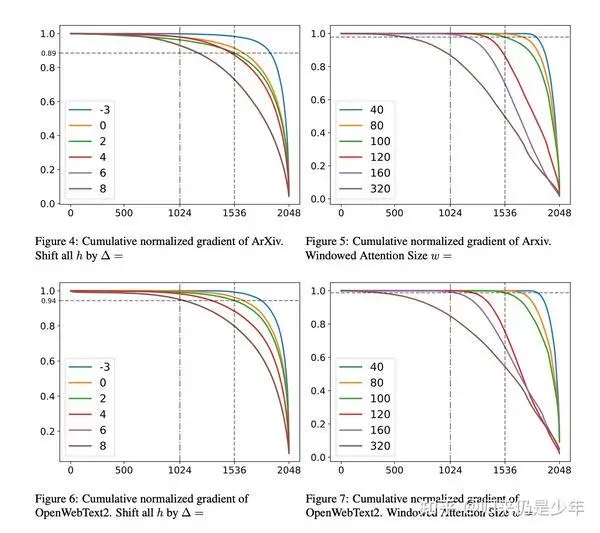 可达到1500tkens前的ppl指标衰减不明显
可达到1500tkens前的ppl指标衰减不明显
Bob 的产品
1.【Bob 的 AI 成长陪伴群】门票 99/年
🔴AI 变现项目、AI 前沿技术、NLP 知识技术分享、前瞻思考、面试技巧、找工作等
🔴 个人 IP 打造、自媒体副业、向上社交、以及我的日常生活所见所闻,所思所想。
2.【一对一的一小时咨询服务】(49/次)
找一群人一起走,慢慢变富。期待和同频的朋友一起蜕变!
3.【简历指导修改】(149/人)
设计多次修改优化.发掘你的潜在价值与内容.
本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!