目录

a
大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪
源码:https://github.com/leo-yangli/VB-LoRA
论文:https://arxiv.org/abs/2405.15179
背景
随着大型语言模型的采用增加以及对每个用户或每个任务模型定制的需求的增长,参数高效微调(PEFT)方法,例如低秩适应(LoRA)及其变体,会产生大量的费用。存储和传输成本。为了进一步减少存储的参数,VB-LoRA 引入了“分而共享”范例,通过向量库全局共享参数,打破了跨矩阵维度、模块和层的低秩分解的障碍。 实现了极高的参数效率,同时保持了可比或更好的性能。
方法论
「LoRA局限性」 LoRA通过在模型的权重矩阵上添加低秩矩阵来调整模型参数,而不是更新整个权重矩阵。尽管LoRA减少了训练参数的数量,但它通常只针对模型中每个权重矩阵单独进行低秩分解,没有实现跨矩阵、跨模块或跨层的参数共享。
本文提出VB-LoRA方法,旨在减少可训练参数量,同时保持模型性能。该方法基础是**「“分而共享(divide-and-share)”」**范式
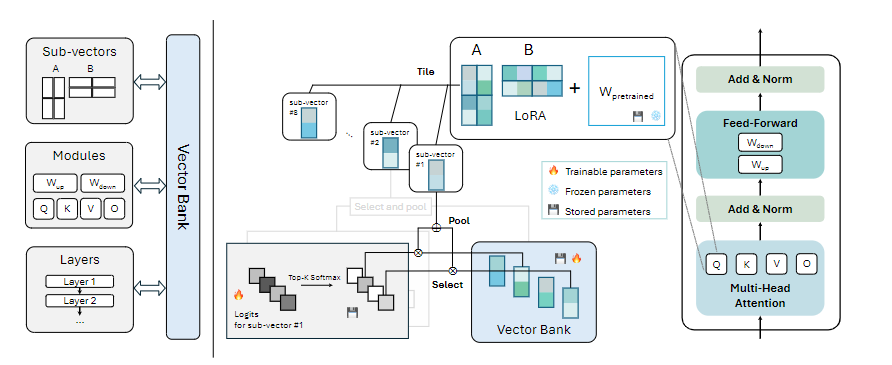
「分解(Divide)」 目的是将LoRA中的低秩矩阵分解成更小的、可管理的组件。这是通过Rank-1分解的形式来实现的,即将一个大的矩阵分解为多个小的Rank-1矩阵的和。每个Rank-1矩阵由两个向量的外积组成,这两个向量分别对应于原始矩阵的行和列。通过这种方式,原始的大矩阵被分解为多个更小的向量,为下一步的共享做准备。
「共享(Share)」 该步骤是“分而共享(divide-and-share)”范式的核心,作者通过一个共享的向量库(Vector Bank),让模型中的不同部分共享相同的参数,从而减少整体参数数量。其中向量库中的向量被设计为可以跨多个子矩阵、模块和层复用。
「向量选择」 对于每个子向量,模型通过一个可学习的logits向量来选择向量库中最重要的k个向量。这个选择过程是通过一个softmax层来实现的,它将logits转换为概率分布,然后选择概率最高的k个向量,并将它们组合成子向量,这些子向量随后被用于构建模型的参数。
通俗一点就是,秩r=1分解降维。多个分解求和得到W
其中:
u₁ = [1, 1, 0, 1]ᵀ v₁ = [2, 1, 0]
u₂ = [0, 1, 1, 0]ᵀ v₂ = [0, 2, 1]
plaintextu₁v₁ᵀ = [2 1 0] [2 1 0] [0 0 0] [2 1 0] u₂v₂ᵀ = [0 0 0] [0 2 1] [0 2 1] [0 0 0] W = u₁v₁ᵀ + u₂v₂ᵀ = [2 1 0] [2 3 1] [0 2 1] [2 1 0]
实验结果
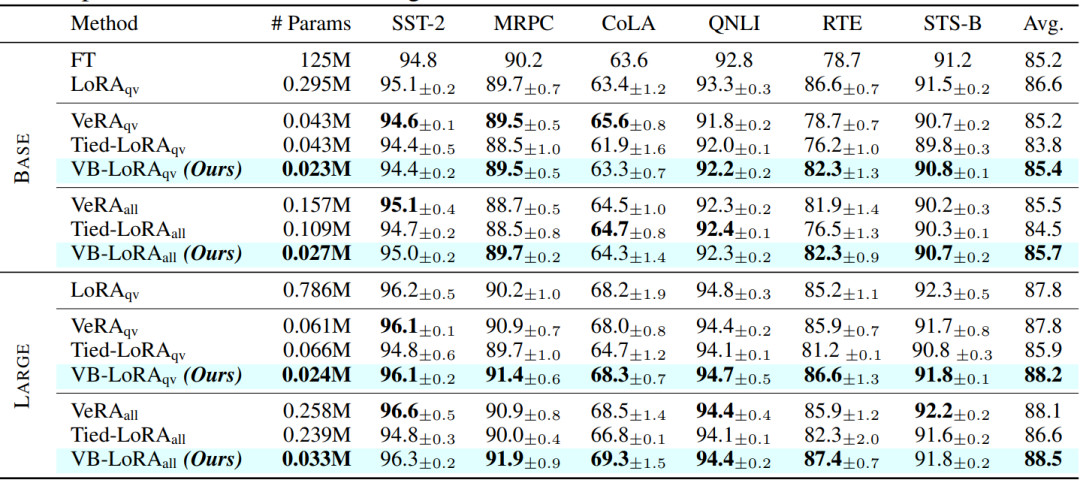
作者使用了GLUE基准测试来评估VB-LoRA在不同自然语言理解任务上的性能。可以看到VB-LoRA在RoBERTa-Large模型上与其他PEFT方法相比,存储参数数量显著减少,但分数更高。
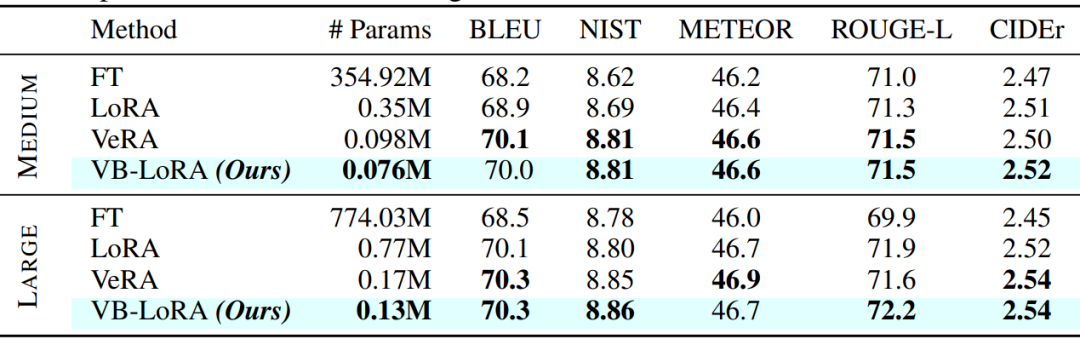
在自然语言生成任务中,本文使用了GPT-2 Medium和Large模型,并在E2E数据集上进行了微调。VB-LoRA在保持与VeRA相当或更好性能的同时,所需的存储参数数量更少。
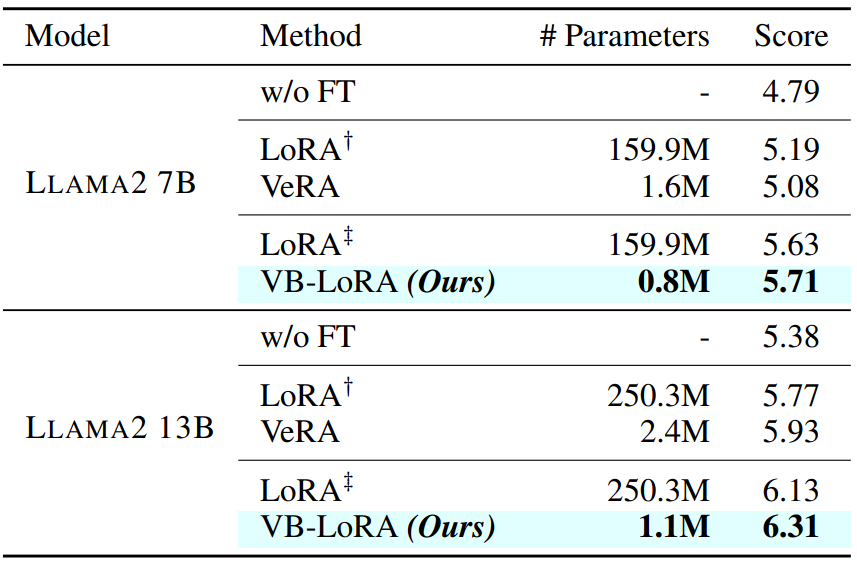
对Llama2模型(7B和13B参数版本)进行微调,VB-LoRA在使用极少的存储参数(Llama2 7B为0.8M,Llama2 13B为1.1M)的情况下,实现了比LoRA更高的分数。
Bob 的产品
1.【Bob 的 AI 成长陪伴群】门票 99/年
🔴AI 变现项目、AI 前沿技术、NLP 知识技术分享、前瞻思考、面试技巧、找工作等
🔴 个人 IP 打造、自媒体副业、向上社交、以及我的日常生活所见所闻,所思所想。
2.一对一的一小时咨询服务(49/次)
找一群人一起走,慢慢变富。期待和同频 朋的 友一起蜕变!
本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!