
大家好,我是 Bob! 😊 一个想和大家慢慢变富的 AI 程序员💸 分享 AI 前沿技术、项目经验、面试技巧! 欢迎关注我,一起探索,一起破圈!💪
链接
https://arxiv.org/pdf/2203.02155
提出动机
GPT-3虽牛,但仍会生成一些带偏见、不真实、有害的负面信息,有时候一本正经胡说八道。这从做研究的角度来看,确实没啥,因为你只要在某个数据集上碾压对手,那就是牛的。但对于工业实践来说,你带有这些问题的话,特别是对于大公司来说,肯定会被用户骂死,骂到产品下线为止。
且GPT-1, GPT-2, GPT-3的主要任务还是续写即文字接龙,不太擅长与听你指令干活。比如,你输入“给我写一份方案”,GPT很可能输出的是“主题是关于如何入门深度学习”,而不是给你生成出一份方案。
InstructGPT因此而提出,它提出了一个叫 “align” 即对齐的概念,指的是使模型输出与人类真是意图更为接近,即对齐,更符合人类偏好。
原文链接:
试验结果前置
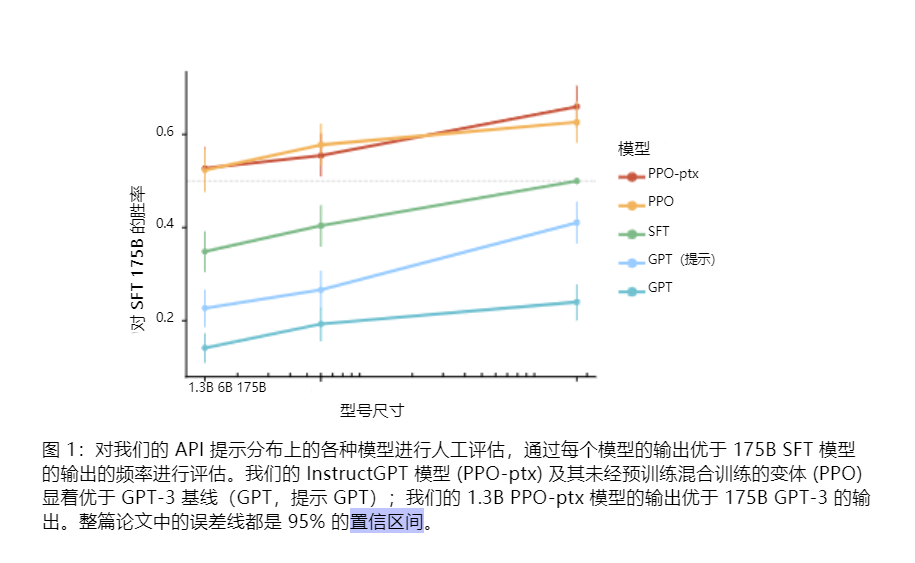
高级方法论(细节)
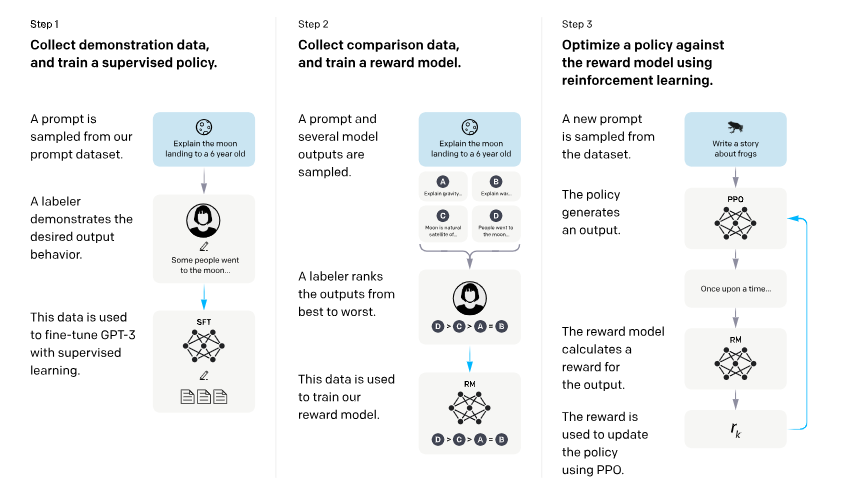
1、SFT有监督微调。
2、训练奖励模型
3、强化学习PPO
步骤一:收集示范数据,训练监督策略。我们的贴标机提供恶魔-输入提示分布上所需行为的示例(有关此分布的详细信息,请参阅第 3.2 节)。然后,我们使用监督学习根据这些数据微调预训练的 GPT-3 模型。
这里InstructGPT的数据为人工标的高质量数据,方法和普通的sft微调没有什么区别,只是为后续提供一个基座模型步骤2:收集比较数据,训练奖励模型。我们收集模型输出之间比较的数据集,其中标记器指示他们对于给定输入更喜欢哪个输出。然后,我们训练奖励模型来预测人类偏好的输出。 ``
步骤 3:使用 PPO 针对奖励模型优化策略。我们使用 RM 的输出作为标量奖励。我们使用 PPO 算法微调监督策略以优化此奖励(Schulman 等人,2017)。
步骤2和步骤3可以不断迭代;收集更多当前最佳策略的比较数据,用于训练新的 RM,然后训练新的策略。实际上,我们的对比数据大部分来自我们的监管政策,也有一些来自我们的PPO政策。
引用
https://blog.csdn.net/weixin_43646592/article/details/130811139
Bob 的产品
1.【Bob 的 AI 成长陪伴群】门票 99/年
🔴AI 变现项目、AI 前沿技术、NLP 知识技术分享、前瞻思考、面试技巧、找工作等
🔴 个人 IP 打造、自媒体副业、向上社交、以及我的日常生活所见所闻,所思所想。
2.一对一的一小时咨询服务(49/次)
找一群人一起走,慢慢变富。期待和同频 朋的 友一起蜕变!
本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!