目录
模型极限压缩论文笔记
这篇论文提出了一种极限压缩大语言模型(LLM)的方法,称为加性量化(Additive Quantization,AQ)。以下是这个量化方法的主要优势、之前方法的缺陷、算法原理以及实验结果:
量化方法的优势
-
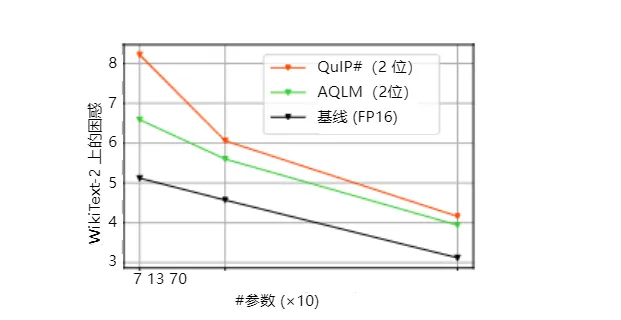
极限压缩:AQLM 可以在每个参数低至 2-3 位的情况下对模型进行压缩。它是第一个在这种极端压缩下依然保持精度和模型大小之间帕累托最优的方案,尤其是在 2 位量化方面表现突出。
-
精度和速度:AQLM 在极低的位数下依然保持了高精度,并且在速度上可以匹配甚至超过优化过的 FP16 实现,同时占用更少的内存空间。
-
实用性:AQLM 提供了 GPU 和 CPU 的高效实现,用于生成文本。它在速度上与浮点数基线相当,内存占用减少了多达 8 倍。
之前的方法(AWQ,GPTQ,SPQR,QUIP)
-
精度损失:现有方法在极端低比特率下会导致显著的精度下降,需要更复杂的实现和更高的运行时开销。
-
模型大小与精度的权衡:低比特率压缩方法常常需要权衡模型大小和精度损失,这在 2 位范围内尤为明显。传统方法在处理 2 位量化时,实用性不如直接使用较小的基础模型并将其量化至更高比特率。
算法原理
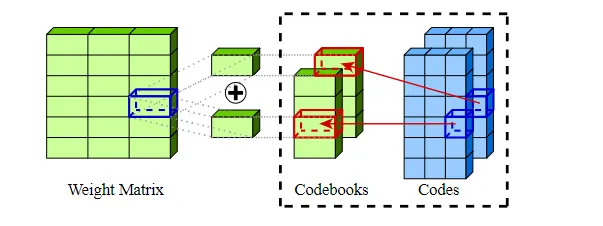
AQLM 方法将加性量化应用到大语言模型的权重矩阵上,并在输入自适应的基础上进行学习,联合优化每个 Transformer 块中的码书参数。该方法基于经典的信息检索中的多码书量化(MCQ)技术:
-
学习加性量化:权重矩阵通过加性量化的方式进行学习,使得量化后的权重矩阵输出可以近似地保持原来的输出。
-
联合优化:对 Transformer 块中的码书参数进行联合优化,以减少量化误差。这种方法避免了需要对异常值进行独立量化,从而保持了简单的同构格式,易于实际应用。
具体的实现:
1. 预处理和初始化
-
权重矩阵分解:将模型的权重矩阵 WWW 分解为多个较小的矩阵,以便于进行量化。假设我们将权重矩阵分解为 KKK 个码书矩阵 CiC_iCi,使得 W≈∑i=1KCiW \approx \sum_{i=1}^K C_iW≈∑i=1KCi。
-
码书初始化:每个码书矩阵 CiC_iCi 都使用随机或其他策略进行初始化,以便后续的优化。
2. 训练阶段
-
码书学习:在训练过程中,通过反向传播和优化算法(如随机梯度下降),同时优化码书矩阵 CiC_iCi 和原始模型的其余参数。目标是最小化量化误差和原始模型输出之间的差距。
-
加性更新:在每个训练步骤中,权重矩阵通过加性更新的方式更新,即 W′=∑i=1KCiW' = \sum_{i=1}^K C_iW′=∑i=1KCi,不断调整码书矩阵以更好地逼近原始权重矩阵。
-
误差反馈:使用误差反馈机制,通过比较量化模型的输出和未量化模型的输出,指导码书矩阵的更新方向和幅度。
3. 量化阶段
-
量化编码:将训练好的码书矩阵进行编码,使其在给定的位宽(如 2 位或 3 位)内表示。每个码书矩阵的值映射到特定的量化级别,以减小表示的浮点数精度。
-
联合优化:通过联合优化技术,调整每个 Transformer 块的码书参数,使得整体模型在量化级别下的输出误差最小化。
实验结果
-
精度表现:AQLM 在标准的 2-4 位压缩范围内的表现都优于之前的最优方法,尤其在极限的 2 位量化中有显著的提升。
-
性能提升:AQLM 可以实现大约 30% 的 GPU 层级加速,并在 CPU 推理中达到高达 4 倍的加速。
综上所述,AQLM 通过引入加性量化和联合优化技术,实现了在极限压缩条件下依然保持高精度和性能的优势。
本文作者:Bob
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!