
Tokenizer之BPE算法的简单实现
编辑
3
2025-04-01
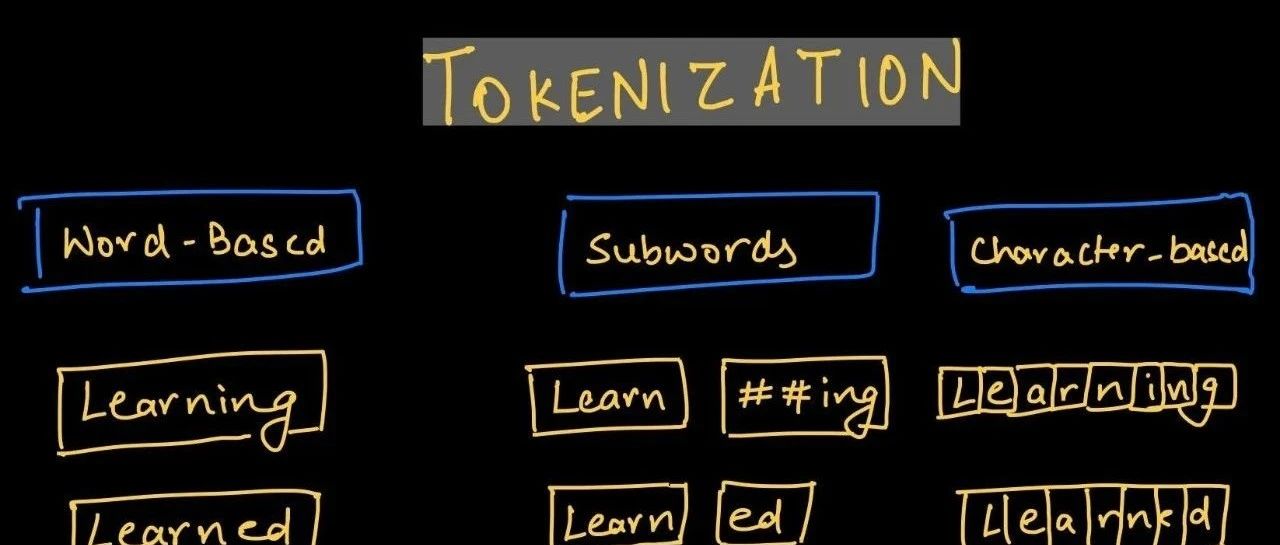
Tokenizer之BPE算法的简单实现
此篇幅较长,基本都是BPE分词代码,可以先了解一下理论篇:
🤗大致流程:
-
• 规范化
-
• 预标记化
-
• 将单词拆分为单个字符
-
• 将学习的合并规则按顺序应用于这些拆分
规范化
标准化步骤涉及一些常规清理,例如删除不必要的空格、小写和/或删除重音符号。如果你熟悉Unicode normalization(例如 NFC 或
NFKC),这也是 tokenizer 可能应用的东西。
🤗Transformers tokenizer 有一个属性叫做 backend_tokenizer 它提供了对 🤗 Tokenizers
库中底层标记器的访问:
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("bert-base-uncased")
print(type(tokenizer.backend_tokenizer))
print(tokenizer.backend_tokenizer.normalizer.normalize_str("Héllò hôw are ü?"))
预标记化
🤗分词器不能单独在原始文本上进行训练。相反,我们首先需要将文本拆分为小实体,例如单词。这就是预标记化步骤的用武之地。正如我们在Chapter 2,
基于单词的标记器可以简单地将原始文本拆分为空白和标点符号的单词。这些词将是分词器在训练期间可以学习的子标记的边界。
要查看快速分词器如何执行预分词,我们可以使用 pre_tokenize_str() 的方法🤗
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
[('Hello', (0, 5)),
(',', (5, 6)),
('how', (7, 10)),
('are', (11, 14)),
('you', (16, 19)),
('?', (19, 20))]
tokenizer = AutoTokenizer.from_pretrained("gpt2")
tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str("Hello, how are you?")
[('Hello', (0, 5)),
(',', (5, 6)),
('Ġhow', (6, 10)),
('Ġare', (10, 14)),
('Ġ', (14, 15)),
('Ġyou', (15, 19)),
('?', (19, 20))]
完整流程
计算词频
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
from collections import defaultdict
word_freqs = defaultdict(int)
for text in corpus:
words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
print(words_with_offsets)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
word_freqs[word] += 1
result:
[('This', (0, 4)), ('Ġis', (4, 7)), ('Ġthe', (7, 11)), ('ĠHugging', (11, 19)), ('ĠFace', (19, 24)), ('ĠCourse', (24, 31)), ('.', (31, 32))]
[('This', (0, 4)), ('Ġchapter', (4, 12)), ('Ġis', (12, 15)), ('Ġabout', (15, 21)), ('Ġtokenization', (21, 34)), ('.', (34, 35))]
[('This', (0, 4)), ('Ġsection', (4, 12)), ('Ġshows', (12, 18)), ('Ġseveral', (18, 26)), ('Ġtokenizer', (26, 36)), ('Ġalgorithms', (36, 47)), ('.', (47, 48))]
[('Hopefully', (0, 9)), (',', (9, 10)), ('Ġyou', (10, 14)), ('Ġwill', (14, 19)), ('Ġbe', (19, 22)), ('Ġable', (22, 27)), ('Ġto', (27, 30)), ('Ġunderstand', (30, 41)), ('Ġhow', (41, 45)), ('Ġthey', (45, 50)), ('Ġare', (50, 54)), ('Ġtrained', (54, 62)), ('Ġand', (62, 66)), ('Ġgenerate', (66, 75)), ('Ġtokens', (75, 82)), ('.', (82, 83))]
print(word_freqs)
result:
defaultdict(<class 'int'>, {'This': 3, 'Ġis': 2, 'Ġthe': 1, 'ĠHugging': 1, 'ĠFace': 1, 'ĠCourse': 1, '.': 4, 'Ġchapter': 1, 'Ġabout': 1, 'Ġtokenization': 1, 'Ġsection': 1, 'Ġshows': 1, 'Ġseveral': 1, 'Ġtokenizer': 1, 'Ġalgorithms': 1, 'Hopefully': 1, ',': 1, 'Ġyou': 1, 'Ġwill': 1, 'Ġbe': 1, 'Ġable': 1, 'Ġto': 1, 'Ġunderstand': 1, 'Ġhow': 1, 'Ġthey': 1, 'Ġare': 1, 'Ġtrained': 1, 'Ġand': 1, 'Ġgenerate': 1, 'Ġtokens': 1})
构建初始词表(最初每一个字符为一个词)
alphabet = []
for word in word_freqs.keys():
for letter in word:
if letter not in alphabet:
alphabet.append(letter)
alphabet.sort()
print(alphabet)
result:
[',', '.', 'C', 'F', 'H', 'T', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'k', 'l', 'm', 'n', 'o', 'p', 'r', 's', 't', 'u', 'v', 'w', 'y', 'z', 'Ġ']
vocab = ["<|endoftext|>"] + alphabet.copy()
拆分每一个词,统计相邻的词对pair
splits = {word: [c for c in word] for word in word_freqs.keys()}
result:
{'This': ['T', 'h', 'i', 's'],
'Ġis': ['Ġ', 'i', 's'],
'Ġthe': ['Ġ', 't', 'h', 'e'],
'ĠHugging': ['Ġ', 'H', 'u', 'g', 'g', 'i', 'n', 'g'],
'ĠFace': ['Ġ', 'F', 'a', 'c', 'e'],
'ĠCourse': ['Ġ', 'C', 'o', 'u', 'r', 's', 'e'],
'.': ['.'],
'Ġchapter': ['Ġ', 'c', 'h', 'a', 'p', 't', 'e', 'r'],
'Ġabout': ['Ġ', 'a', 'b', 'o', 'u', 't'],
'Ġtokenization': ['Ġ',
't',
'o',
'k',
'e',
'n',
'i',
'z',
'a',
't',
'i',
'o',
'n'],
'Ġsection': ['Ġ', 's', 'e', 'c', 't', 'i', 'o', 'n'],
'Ġshows': ['Ġ', 's', 'h', 'o', 'w', 's'],
'Ġseveral': ['Ġ', 's', 'e', 'v', 'e', 'r', 'a', 'l'],
'Ġtokenizer': ['Ġ', 't', 'o', 'k', 'e', 'n', 'i', 'z', 'e', 'r'],
'Ġalgorithms': ['Ġ', 'a', 'l', 'g', 'o', 'r', 'i', 't', 'h', 'm', 's'],
'Hopefully': ['H', 'o', 'p', 'e', 'f', 'u', 'l', 'l', 'y'],
',': [','],
'Ġyou': ['Ġ', 'y', 'o', 'u'],
'Ġwill': ['Ġ', 'w', 'i', 'l', 'l'],
'Ġbe': ['Ġ', 'b', 'e'],
'Ġable': ['Ġ', 'a', 'b', 'l', 'e'],
'Ġto': ['Ġ', 't', 'o'],
'Ġunderstand': ['Ġ', 'u', 'n', 'd', 'e', 'r', 's', 't', 'a', 'n', 'd'],
'Ġhow': ['Ġ', 'h', 'o', 'w'],
'Ġthey': ['Ġ', 't', 'h', 'e', 'y'],
'Ġare': ['Ġ', 'a', 'r', 'e'],
'Ġtrained': ['Ġ', 't', 'r', 'a', 'i', 'n', 'e', 'd'],
'Ġand': ['Ġ', 'a', 'n', 'd'],
'Ġgenerate': ['Ġ', 'g', 'e', 'n', 'e', 'r', 'a', 't', 'e'],
'Ġtokens': ['Ġ', 't', 'o', 'k', 'e', 'n', 's']}
def compute_pair_freqs(splits):
pair_freqs = defaultdict(int)
for word, freq in word_freqs.items():
split = splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
pair_freqs=compute_pair_freqs(splits)
result:
defaultdict(int,
{('T', 'h'): 3,
('h', 'i'): 3,
('i', 's'): 5,
('Ġ', 'i'): 2,
('Ġ', 't'): 7,
('t', 'h'): 3,
('h', 'e'): 2,
('Ġ', 'H'): 1,
('H', 'u'): 1,
('u', 'g'): 1,
('g', 'g'): 1,
('g', 'i'): 1,
('i', 'n'): 2,
('n', 'g'): 1,
('Ġ', 'F'): 1,
('F', 'a'): 1,
('a', 'c'): 1,
('c', 'e'): 1,
('Ġ', 'C'): 1,
('C', 'o'): 1,
('o', 'u'): 3,
('u', 'r'): 1,
('r', 's'): 2,
('s', 'e'): 3,
('Ġ', 'c'): 1,
('c', 'h'): 1,
('h', 'a'): 1,
('a', 'p'): 1,
('p', 't'): 1,
('t', 'e'): 2,
('e', 'r'): 5,
('Ġ', 'a'): 5,
('a', 'b'): 2,
('b', 'o'): 1,
('u', 't'): 1,
('t', 'o'): 4,
('o', 'k'): 3,
('k', 'e'): 3,
('e', 'n'): 4,
('n', 'i'): 2,
('i', 'z'): 2,
('z', 'a'): 1,
('a', 't'): 2,
('t', 'i'): 2,
('i', 'o'): 2,
('o', 'n'): 2,
('Ġ', 's'): 3,
('e', 'c'): 1,
('c', 't'): 1,
('s', 'h'): 1,
('h', 'o'): 2,
('o', 'w'): 2,
('w', 's'): 1,
('e', 'v'): 1,
('v', 'e'): 1,
('r', 'a'): 3,
('a', 'l'): 2,
('z', 'e'): 1,
('l', 'g'): 1,
('g', 'o'): 1,
('o', 'r'): 1,
('r', 'i'): 1,
('i', 't'): 1,
('h', 'm'): 1,
('m', 's'): 1,
('H', 'o'): 1,
('o', 'p'): 1,
('p', 'e'): 1,
('e', 'f'): 1,
('f', 'u'): 1,
('u', 'l'): 1,
('l', 'l'): 2,
('l', 'y'): 1,
('Ġ', 'y'): 1,
('y', 'o'): 1,
('Ġ', 'w'): 1,
('w', 'i'): 1,
('i', 'l'): 1,
('Ġ', 'b'): 1,
('b', 'e'): 1,
('b', 'l'): 1,
('l', 'e'): 1,
('Ġ', 'u'): 1,
('u', 'n'): 1,
('n', 'd'): 3,
('d', 'e'): 1,
('s', 't'): 1,
('t', 'a'): 1,
('a', 'n'): 2,
('Ġ', 'h'): 1,
('e', 'y'): 1,
('a', 'r'): 1,
('r', 'e'): 1,
('t', 'r'): 1,
('a', 'i'): 1,
('n', 'e'): 2,
('e', 'd'): 1,
('Ġ', 'g'): 1,
('g', 'e'): 1,
('n', 's'): 1})
计算出现最多的词对pair
fbest_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
print(best_pair, max_freq)
result:
('Ġ', 't') 7
合并字词,更新词表
def merge_pair(a, b, splits):
for word in word_freqs:
split = splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
splits[word] = split
return splits
```
```
splits = merge_pair("Ġ", "t", splits)
print(splits["Ġtrained"])
reuslt:
['Ġt', 'r', 'a', 'i', 'n', 'e', 'd']
vocab_size = 100
merges={}
while len(vocab) < vocab_size:
pair_freqs = compute_pair_freqs(splits)
best_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
splits = merge_pair(*best_pair, splits)
merges[best_pair] = best_pair[0] + best_pair[1]
vocab.append(best_pair[0] + best_pair[1])
所有代码整合成类
from collections import defaultdict
from transformers import AutoTokenizer
import json
class BPE_tokenizer:
def __init__(self, corpus, vocab_size=100):
self.corpus = corpus
self.vocab_size = vocab_size
self.tokenizer = AutoTokenizer.from_pretrained("gpt2")
self.word_freqs = defaultdict(int)
self.vocab = ["<|endoftext|>"]
self.splits = {}
self.merges = {}
if corpus is not None:
self._compute_word_freqs()
self._build_alphabet()
self._train()
def _compute_word_freqs(self):
for text in self.corpus:
words_with_offsets = self.tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
new_words = [word for word, offset in words_with_offsets]
for word in new_words:
self.word_freqs[word] += 1
def _build_alphabet(self):
alphabet = []
for word in self.word_freqs.keys():
for letter in word:
if letter not in alphabet:
alphabet.append(letter)
alphabet.sort()
self.vocab.extend(alphabet)
self.splits = {word: [c for c in word] for word in self.word_freqs.keys()}
def _compute_pair_freqs(self):
pair_freqs = defaultdict(int)
for word, freq in self.word_freqs.items():
split = self.splits[word]
if len(split) == 1:
continue
for i in range(len(split) - 1):
pair = (split[i], split[i + 1])
pair_freqs[pair] += freq
return pair_freqs
def _get_best_pair(self, pair_freqs):
best_pair = ""
max_freq = None
for pair, freq in pair_freqs.items():
if max_freq is None or max_freq < freq:
best_pair = pair
max_freq = freq
return best_pair, max_freq
def _merge_pair(self, a, b):
for word in self.word_freqs:
split = self.splits[word]
if len(split) == 1:
continue
i = 0
while i < len(split) - 1:
if split[i] == a and split[i + 1] == b:
split = split[:i] + [a + b] + split[i + 2 :]
else:
i += 1
self.splits[word] = split
def _train(self):
while len(self.vocab) < self.vocab_size:
pair_freqs = self._compute_pair_freqs()
best_pair, _ = self._get_best_pair(pair_freqs)
self._merge_pair(*best_pair)
self.merges[best_pair] = best_pair[0] + best_pair[1]
self.vocab.append(best_pair[0] + best_pair[1])
def tokenize(self, text):
pre_tokenize_result = self.tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
pre_tokenized_text = [word for word, offset in pre_tokenize_result]
splits = [[l for l in word] for word in pre_tokenized_text]
for pair, merge in self.merges.items():
for idx, split in enumerate(splits):
i = 0
while i < len(split) - 1:
if split[i] == pair[0] and split[i + 1] == pair[1]:
split = split[:i] + [merge] + split[i + 2 :]
else:
i += 1
splits[idx] = split
return sum(splits, [])
def save(self, filepath='tokenizer.json'):
"""保存分词器到文件(JSON格式)"""
state = {
'vocab_size': self.vocab_size,
'word_freqs': dict(self.word_freqs),
'vocab': self.vocab,
'splits': self.splits,
'merges': {str(k): v for k, v in self.merges.items()} # 将元组键转换为字符串
}
with open(filepath, 'w', encoding='utf-8') as f:
json.dump(state, f, ensure_ascii=False, indent=2)
@classmethod
def load(cls, filepath):
"""从文件加载分词器(JSON格式)"""
with open(filepath, 'r', encoding='utf-8') as f:
state = json.load(f)
tokenizer = cls()
tokenizer.vocab_size = state['vocab_size']
tokenizer.word_freqs = defaultdict(int, state['word_freqs'])
tokenizer.vocab = state['vocab']
tokenizer.splits = state['splits']
tokenizer.merges = {tuple(k.split("', '")): v for k, v in state['merges'].items()} # 将字符串键转换回元组
return tokenizer
示例
# 定义语料库
corpus = [
"This is the Hugging Face Course.",
"This chapter is about tokenization.",
"This section shows several tokenizer algorithms.",
"Hopefully, you will be able to understand how they are trained and generate tokens.",
]
# 创建 BPE_tokenizer 实例
tokenizer = BPE_tokenizer(corpus, vocab_size=100)
# 使用 tokenizer 对新文本进行分词
text = "This is a new sentence to tokenize."
tokens = tokenizer.tokenize(text)
print(tokens)
···
- 0
- 0
-
分享